Perl 로그인 로그아웃 예제 정리
본 시리즈에서는 웹 개발을 할 때 자주 사용되는 기능인 로그인/로그아웃 기능에 대한 예제를 정리한다. 아이디와 암호가 일치할 경우 이 상태를 쿠키cookie나 세션session에 기억시키고, 이후 페이지 접속 시 해당 쿠키 또는 세션의 보유 여부에 따라 로그인한 이용자와 로그인하지 않은 이용자를 구분하고 서로 다른 페이지를 보여주도록 하는 것이 본 시리즈에서 구현하는 주된 기능이다.
- Perl 로그인 로그아웃 예제 정리 (part 01 - 쿠키를 사용한 예)
- Perl 로그인 로그아웃 예제 정리 (part 02 - 세션을 사용한 예) [完]
- PHP 로그인 로그아웃 예제 정리 (part 01 - 쿠키를 사용한 예)
- PHP 로그인 로그아웃 예제 정리 (part 02 - 세션을 사용한 예) [完]
- JSP 로그인 로그아웃 예제 정리 (part 01 - 쿠키를 사용한 예)
- JSP 로그인 로그아웃 예제 정리 (part 02 - 세션을 사용한 예) [完]
- ASP 로그인 로그아웃 예제 정리 (part 01 - 쿠키를 사용한 예)
- ASP 로그인 로그아웃 예제 정리 (part 02 - 세션을 사용한 예) [完]
- ASP.NET 로그인 로그아웃 예제 정리 (part 01 - 쿠키를 사용한 예)
- ASP.NET 로그인 로그아웃 예제 정리 (part 02 - 세션을 사용한 예) [完]
Part II. 세션을 사용한 로그인, 로그아웃 (Perl)
본 게시물에서는 Perl(CGI) 소스 코드로 세션에 의한 로그인/로그아웃 기능을 구현한다. 로그인 화면에서 아이디와 암호를 맞게 입력했다면 서버에 로그인 정보를 보관하고 이 정보에 접근할 수 있는 식별 번호를 클라이언트의 쿠키로 전송한다. 이후 클라이언트는 페이지를 접속할 때마다 쿠키를 통해 세션 번호를 서버에 전달하고, 서버는 해당 번호의 세션이 보유한 유효성 여부를 판별하여 회원 페이지를 보여줄 것인지, 비회원 페이지를 보여줄 것인지를 결정하게 된다.
<Prologue>
CGI의 세션 기능을 사용하기 위해서는 CGI::Session 모듈을 설치해야 한다. 기본적으로 cpan install CGI::Session을 통해 설치할 수도 있지만 운영체제와의 원활한 연계를 위해 패키지 형태로 설치할 것이 권장된다.
RedHat 계열의 운영체제 (예: CentOS)는 터미널에서 다음의 명령을 실행한다.
$ sudo yum install perl-CGI-SessionDebian 계열의 운영체제 (예: Ubuntu)는 터미널에서 다음의 명령을 실행한다.
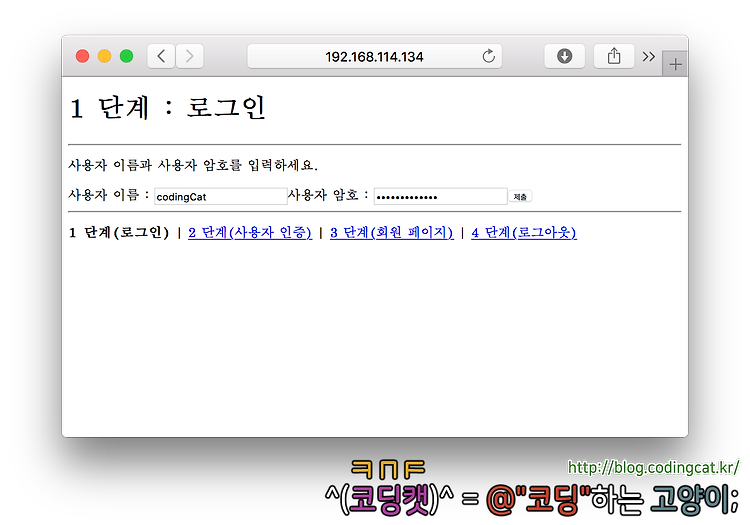
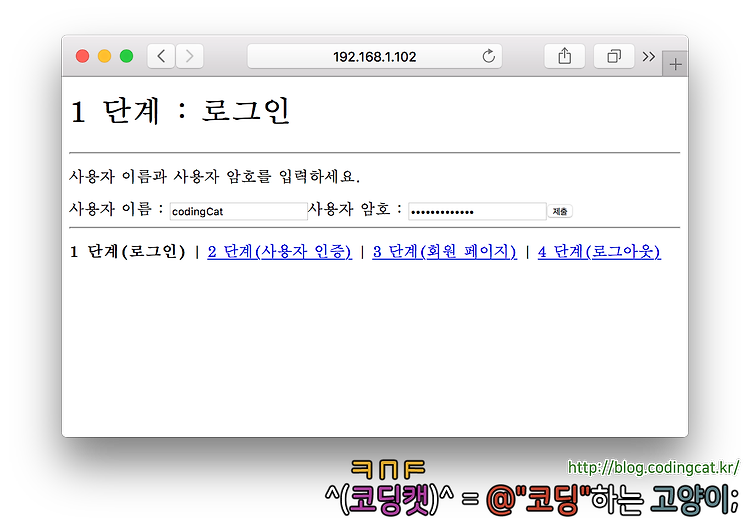
$ sudo apt install libcgi-session-perlstep1.cgi - 로그인 화면
이 페이지를 통해 사용자로부터 아이디와 암호를 입력받는다. 아이디가 전달될 매개변수 이름은 trialUsername이라 하고 암호가 전달될 매개변수 이름은 trialPassword라 이름 붙인다. 예제 소스 코드의 구조를 단순하게 하기 위하여 아이디와 암호에 대한 보안 조치 등은 생략한 채 쿠키와 POST 데이터를 통해 직접 사용자 이름과 암호가 전달될 것이다.
#!/usr/bin/perl
use CGI qw/:standard/;
print "Content-type: text/html; charset=UTF-8\n\n";
################################################################################
# 웹 페이지 본문 영역
print "<!DOCTYPE html>";
print "<html lang='ko'>";
print "<head>";
print "<meta charset='UTF-8' />";
print "<title>1 단계 : 로그인</title>";
print "</head>";
print "<body>";
print "<header>";
print "<h1>1 단계 : 로그인</h1>";
print "</header>";
print "<hr />";
print "<section>";
print "<p>사용자 이름과 사용자 암호를 입력하세요.</p>";
print "<form action='./step2.cgi' method='post'>";
print "<label for='trialUsername'>사용자 이름 : </label><input type='text' id='trialUsername' name='trialUsername' />";
print "<label for='trialPassword'>사용자 암호 : </label><input type='password' id='trialPassword' name='trialPassword' />";
print "<input type='submit' />";
print "</form>";
print "</section>";
print "<hr />";
print "<footer>";
print "<p>";
print "<span><a href='./step1.cgi'>1 단계(로그인)</a> | </span>";
print "<span><strong>2 단계(사용자 인증)</strong> | </span>";
print "<span><a href='./step3.cgi'>3 단계(회원 페이지)</a> | </span>";
print "<span><a href='./step4.cgi'>4 단계(로그아웃)</a></span>";
print "</p>";
print "</footer>";
print "</body>";
print "</html>";
위 소스 코드에서는 사용자 이름과 암호를 입력받는 폼form을 출력한다. name 속성이 각각 trialUsername과 trialPassword인 input을 통해 사용자 이름과 암호를 입력받은 뒤 POST 방식으로 다음 파일인 step2.cgi로 전달할 것이다.
step2.cgi - 사용자 인증
이 페이지는 step1.cgi에서 전달된 아이디(trialUsername)/암호(trialPassword)가 미리 준비된 아이디(authorizedUsername)/암호(authorizedPassword)와 일치하는지 여부를 검사할 것이다. 일치하면 membershipUsername와 membershipPassword라는 세션 변수에 각각 아이디와 암호를 보관하고, 해당 세션의 식별번호를 쿠키를 통해 클라이언트로 전송할 것이다. 일치하지 않으면 별도의 오류 메시지를 보여줄 것이다.
#!/usr/bin/perl
use CGI qw/:standard/;
use CGI::Cookie;
use CGI::Session;
################################################################################
# 사용자 인증 로직
# 이름과 암호를 비교하며 승인되면 nonzero, 승인 안 되면 zero를 반환한다.
# 아래 이름의 사용자면 로그인 승인 함.
my $authorizedUsername = "codingCat";
# 아래의 암호를 입력하면 로그인 승인 함.
my $authorizedPassword = "qwerty123456!";
# 로그인 승인 시 nonzero, 아니면 zero
my $authorizeStatus = 0;
# authorizeMembership(-trialUsername, -trialPassword)
# 사용자 이름과 암호를 비교하여 로그인 승인 여부를 결정하는 서브루틴.
# -trialUsername : 로그인을 시도하는 사용자 이름
# -trialPassword : 로그인을 시도하는 사용자가 입력한 암호
# 로그인 승인하면 nonzero를 반환하고 승인 거부 시 zero를 반환한다.
sub authorizeMembership(@)
{
my %args = @_;
my $trialUsername = $args{"-trialUsername"};
my $trialPassword = $args{"-trialPassword"};
# 로그인 요청하는 사용자 이름이 미리 지정된 이름과 같은지 검사
if ($trialUsername eq $authorizedUsername)
{
# 이름이 일치하면, 암호가 같은지 검사
if ($trialPassword eq $authorizedPassword)
{
# 이름과 암호가 모두 일치하면 로그인 승인
return 1;
}
}
# 그렇지 않을 경우 로그인 거부
return 0;
}
################################################################################
# 웹 페이지 헤더 영역
# 이전 페이지에서 POST 방식으로 전송된 사용자 이름 및 암호를 읽어온다.
$trialUsername = undef;
$trialPassword = undef;
# CGI 객체를 생성한다.
$objectCGI = new CGI;
# 서버에 저장된 세션 객체이다.
$objectSession = undef;
# 클라이언트로 전송할 쿠키이다.
$objectCookie = undef;
$authorizeStatus = 0;
# POST 방식으로 전달된 데이터 중 trialUsername이라는 데이터가 있는지 확인
if ($objectCGI->param("trialUsername") ne undef)
{
# trialUsername이 존재하면, trialPassword라는 데이터도 있는지 확인
if ($objectCGI->param("trialPassword") ne undef)
{
# POST 데이터에서 얻은 사용자 이름과 암호로 로그인 상태가 유효한지 검증
$trialUsername = $objectCGI->param("trialUsername");
$trialPassword = $objectCGI->param("trialPassword");
# trialUsername과 trialPassword가 모두 수신되면,
# 앞서 정의된 authorizeMembership 메서드로 로그인 요청한다.
$authorizeStatus = authorizeMembership
(
-trialUsername=>$trialUsername,
-trialPassword=>$trialPassword
);
}
}
# 로그인 요청이 승인되었다면
if ($authorizeStatus)
{
# 세션 객체를 생성한다.
$objectSession = new CGI::Session
(
"driver:File",
undef,
{Directory=>"/tmp"}
);
# membershipUsername이라 이름붙인 세션 변수에
# 사용자 이름을 기록한다.
$objectSession->param("membershipUsername", $trialUsername);
# membershipPassword이라 이름붙인 세션 변수에
# 사용자 암호를 기록한다.
$objectSession->param("membershipPassword", $trialPassword);
# 세션의 유효 기간은 현재 시점으로부터 12시간이다.
$objectSession->expire("+12h");
# 현재의 편집 상태를 세션으로 저장한다.
$objectSession->flush();
# 세션을 생성할 때 발급된 세션 ID를 CGISESSID라는 쿠키변수로써 클라이언트에 전달한다.
# 여기에서는 쿠키의 유효 기간도 세션과 마찬가지로 12시간으로 정한다.
$objectCookie = new CGI::Cookie
(
-name=>"CGISESSID",
-value=>($objectSession->id),
-expires=>"+12h"
);
# 쿠키는 HTTP 헤더 부분에 명시되어야 하므로 웹 페이지의 본문에 앞서 이를 출력함
print "Set-Cookie: ", $objectCookie->as_string, "\n";
}
print "Content-type: text/html; charset=UTF-8\n\n";
################################################################################
# 웹 페이지 본문 영역
print "<!DOCTYPE html>";
print "<html lang='ko'>";
print "<head>";
print "<meta charset='UTF-8' />";
print "<title>2 단계 : 사용자 인증</title>";
print "</head>";
print "<body>";
print "<header>";
print "<h1>2 단계 : 사용자 인증</h1>";
print "</header>";
print "<hr />";
print "<section>";
if ($authorizeStatus)
{
# 로그인 승인 되었다면...
print "<p>로그인에 성공했습니다.</p>";
print "<p>쿠키 문자열</p>";
print "<pre><code>", $objectCookie->as_string, "</code></pre>";
print "<p><a href='./step3.cgi'>회원 페이지</a></p>";
}
else
{
# 로그인 거부 되었다면...
print "<p>로그인에 실패했습니다.</p>";
print "<p><a href='./step1.cgi'>로그인 화면</a></p>";
}
print "</section>";
print "<hr />";
print "<footer>";
print "<p>";
print "<span><a href='./step1.cgi'>1 단계(로그인)</a> | </span>";
print "<span><strong>2 단계(사용자 인증)</strong> | </span>";
print "<span><a href='./step3.cgi'>3 단계(회원 페이지)</a> | </span>";
print "<span><a href='./step4.cgi'>4 단계(로그아웃)</a></span>";
print "</p>";
print "</footer>";
print "</body>";
print "</html>";

로그인이 정상적이라면 서버의 특정 경로에 세션에 대한 데이터가 생성되어있음을 확인할 수 있다. CentOS를 기준으로 /tmp/systemd-private-...-httpd.service-.../<디렉터리명>이다. 여기서 <디렉터리명>란 perl 코드에서 세션 객체를 생성할 때 { Directory=> "..." }로 지정한 이름이다. 세션이 유지되는 동안 root 권한으로 이 디렉터리를 들어가면 cgisess_<세션식별번호>라는 이름의 텍스트 파일이 아래와 같이 존재할 것이다.

vi로 이 파일을 열었을 때 다음과 같이 사용자 이름, 사용자 암호, 만료시간 등의 각종 세션변수가 기록되어 있음을 확인할 수 있다. 쿠키를 사용하여 클라이언트로 전달되는 내용은 아래의 내용 자체가 아니라 아래의 내용에 접근할 수 있는 고유번호만을 전달할 뿐이므로 쿠키만을 사용하는 로그인보다는 안전하다고 볼 수 있다.

step3.cgi - 회원 전용 페이지
클라이언트 측으로부터 쿠키에 보관된 세션 식별 번호를 전달받는다. 서버의 특정 위치에서 해당 번호를 갖는 세션을 읽어온 후, 로그인 상태임이 확인되면 회원 전용 페이지를 출력한다. 그렇지 않다면 비회원용 페이지를 출력한다.
#!/usr/bin/perl
use CGI qw/:standard/;
use CGI::Cookie;
use CGI::Session;
################################################################################
# 사용자 인증 로직
# 이름과 암호를 비교하며 승인되면 nonzero, 승인 안 되면 zero를 반환한다.
# 아래 이름의 사용자면 로그인 승인 함.
my $authorizedUsername = "codingCat";
# 아래의 암호를 입력하면 로그인 승인 함.
my $authorizedPassword = "qwerty123456!";
# 로그인 승인 시 nonzero, 아니면 zero
my $authorizeStatus = 0;
# authorizeMembership(-trialUsername, -trialPassword)
# 사용자 이름과 암호를 비교하여 로그인 승인 여부를 결정하는 서브루틴.
# -trialUsername : 로그인을 시도하는 사용자 이름
# -trialPassword : 로그인을 시도하는 사용자가 입력한 암호
# 로그인 승인하면 nonzero를 반환하고 승인 거부 시 zero를 반환한다.
sub authorizeMembership(@)
{
my %args = @_;
my $trialUsername = $args{"-trialUsername"};
my $trialPassword = $args{"-trialPassword"};
# 로그인 요청하는 사용자 이름이 미리 지정된 이름과 같은지 검사
if ($trialUsername eq $authorizedUsername)
{
# 이름이 일치하면, 암호가 같은지 검사
if ($trialPassword eq $authorizedPassword)
{
# 이름과 암호가 모두 일치하면 로그인 승인
return 1;
}
}
# 그렇지 않을 경우 로그인 거부
return 0;
}
################################################################################
# 웹 페이지 헤더 영역
# 세션에 저장된 사용자 이름 및 암호를 읽어온다.
$membershipUsername = undef;
$membershipPassword = undef;
# CGI 객체를 생성한다.
$objectCGI = new CGI;
# 서버에 저장된 세션 객체이다.
$objectSession = undef;
# 클라이언트로 전송할 쿠키이다.
$objectCookie = undef;
# 본 페이지로 전달된 쿠키를 확인한다.
%objectCookies = fetch CGI::Cookie;
$authorizeStatus = 0;
# 쿠키가 존재하면
# 로그인 유효성 검사 : 클라이언트의 쿠키가 본 페이지에 전달한 로그인 정보를 검증한다.
if (%objectCookies ne undef)
{
# 쿠키 변수 중에 CGISESSID라는 데이터가 있는지 확인
if ($objectCookies{"CGISESSID"} ne undef)
{
# 세션 객체를 생성한다.
$objectSession = new CGI::Session
(
undef,
(scalar $objectCookies{"CGISESSID"}->value),
{Directory=>"/tmp"}
);
# 세션 변수 중 membershipUsername이라는 데이터가 있는지 확인
if ($objectSession->param("membershipUsername") ne undef)
{
# membershipUsername이 존재하면, membershipPassword라는 데이터도 있는지 확인
if ($objectSession->param("membershipPassword") ne undef)
{
# 세션 변수에서 얻은 사용자 이름과 암호로 로그인 상태가 유효한지 검증
$membershipUsername = $objectSession->param("membershipUsername");
$membershipPassword = $objectSession->param("membershipPassword");
# membershipUsername과 membershipPassword가 모두 수신되면,
# 앞서 정의된 authorizeMembership 메서드로 로그인 요청한다.
$authorizeStatus = authorizeMembership
(
-trialUsername=>$membershipUsername,
-trialPassword=>$membershipPassword
);
}
}
}
}
# 로그인 요청이 승인되었다면
if ($authorizeStatus)
{
# membershipUsername이라 이름붙인 세션 변수에
# 사용자 이름을 기록한다.
$objectSession->param("membershipUsername", $membershipUsername);
# membershipPassword이라 이름붙인 세션 변수에
# 사용자 암호를 기록한다.
$objectSession->param("membershipPassword", $membershipPassword);
# 세션의 유효 기간은 현재 시점으로부터 12시간이다.
$objectSession->expire("+12h");
# 현재의 편집 상태를 세션으로 저장한다.
$objectSession->flush();
# 세션을 생성할 때 발급된 세션 ID를 CGISESSID라는 쿠키 변수로써 클라이언트에 전달한다.
# 여기에서는 쿠키의 유효 기간도 세션과 마찬가지로 12시간으로 정한다.
$objectCookie = new CGI::Cookie
(
-name=>"CGISESSID",
-value=>($objectSession->id),
-expires=>"+12h"
);
# 쿠키는 HTTP 헤더 부분에 명시되어야 하므로 웹 페이지의 본문에 앞서 이를 출력함
print "Set-Cookie: ", $objectCookie->as_string, "\n";
}
print "Content-type: text/html; charset=UTF-8\n\n";
################################################################################
# 웹 페이지 본문 영역
print "<!DOCTYPE html>";
print "<html lang='ko'>";
print "<head>";
print "<meta charset='UTF-8' />";
print "<title>3 단계 : 회원 페이지</title>";
print "</head>";
print "<body>";
print "<header>";
print "<h1>3 단계 : 회원 페이지</h1>";
print "</header>";
print "<hr />";
print "<section>";
if ($authorizeStatus)
{
# 로그인 승인 되었다면...
print "<p>회원 전용 페이지</p>";
print "<p>환영합니다. $membershipUsername 님.</p>";
print "<p>쿠키 문자열 :</p>";
print "<pre><code>$ENV{'HTTP_COOKIE'}</code></pre>";
print "<p><a href='./step4.cgi'>로그아웃</a></p>";
}
else
{
# 로그인 거부 되었다면...
print "<p>이 페이지를 보려면 로그인이 필요합니다.</p>";
print "<p><a href='./step1.cgi'>로그인</a></p>";
}
print "</section>";
print "<hr />";
print "<footer>";
print "<p>";
print "<span><a href='./step1.cgi'>1 단계(로그인)</a> | </span>";
print "<span><strong>2 단계(사용자 인증)</strong> | </span>";
print "<span><a href='./step3.cgi'>3 단계(회원 페이지)</a> | </span>";
print "<span><a href='./step4.cgi'>4 단계(로그아웃)</a></span>";
print "</p>";
print "</footer>";
print "</body>";
print "</html>";


step4.cgi - 로그아웃 화면
로그인 상태임이 확인되면 서버의 세션을 삭제하고 클라이언트의 쿠키를 만료시켜서 로그아웃 작업을 수행한다. 그렇지 않은 경우 이미 로그아웃 상태임을 알려준다.
#!/usr/bin/perl
use CGI qw/:standard/;
use CGI::Cookie;
use CGI::Session;
################################################################################
# 사용자 인증 로직
# 이름과 암호를 비교하며 승인되면 nonzero, 승인 안 되면 zero를 반환한다.
# 아래 이름의 사용자면 로그인 승인 함.
my $authorizedUsername = "codingCat";
# 아래의 암호를 입력하면 로그인 승인 함.
my $authorizedPassword = "qwerty123456!";
# 로그인 승인 시 nonzero, 아니면 zero
my $authorizeStatus = 0;
# authorizeMembership(-trialUsername, -trialPassword)
# 사용자 이름과 암호를 비교하여 로그인 승인 여부를 결정하는 서브루틴.
# -trialUsername : 로그인을 시도하는 사용자 이름
# -trialPassword : 로그인을 시도하는 사용자가 입력한 암호
# 로그인 승인하면 nonzero를 반환하고 승인 거부 시 zero를 반환한다.
sub authorizeMembership(@)
{
my %args = @_;
my $trialUsername = $args{"-trialUsername"};
my $trialPassword = $args{"-trialPassword"};
# 로그인 요청하는 사용자 이름이 미리 지정된 이름과 같은지 검사
if ($trialUsername eq $authorizedUsername)
{
# 이름이 일치하면, 암호가 같은지 검사
if ($trialPassword eq $authorizedPassword)
{
# 이름과 암호가 모두 일치하면 로그인 승인
return 1;
}
}
# 그렇지 않을 경우 로그인 거부
return 0;
}
################################################################################
# 웹 페이지 헤더 영역
# 클라이언트의 쿠키로부터 전송된 사용자 이름 및 암호를 읽어온다.
$membershipUsername = undef;
$membershipPassword = undef;
# CGI 객체를 생성한다.
$objectCGI = new CGI;
# 서버에 저장된 세션 객체이다.
$objectSession = undef;
# 클라이언트로 전송할 쿠키이다.
$objectCookie = undef;
# 본 페이지로 전달된 쿠키를 확인한다.
%objectCookies = fetch CGI::Cookie;
$authorizeStatus = 0;
# 쿠키가 존재하면
# 로그인 유효성 검사 : 클라이언트의 쿠키가 본 페이지에 전달한 로그인 정보를 검증한다.
if (%objectCookies ne undef)
{
# 쿠키 변수 중에 CGISESSID라는 데이터가 있는지 확인
if ($objectCookies{"CGISESSID"} ne undef)
{
# 세션 객체를 생성한다.
$objectSession = new CGI::Session
(
undef,
(scalar $objectCookies{"CGISESSID"}->value),
{Directory=>"/tmp"}
);
# 세션 변수 중 membershipUsername이라는 데이터가 있는지 확인
if ($objectSession->param("membershipUsername") ne undef)
{
# membershipUsername이 존재하면, membershipPassword라는 데이터도 있는지 확인
if ($objectSession->param("membershipPassword") ne undef)
{
# 세션 변수에서 얻은 사용자 이름과 암호로 로그인 상태가 유효한지 검증
$membershipUsername = $objectSession->param("membershipUsername");
$membershipPassword = $objectSession->param("membershipPassword");
# membershipUsername과 membershipPassword가 모두 수신되면,
# 앞서 정의된 authorizeMembership 메서드로 로그인 요청한다.
$authorizeStatus = authorizeMembership
(
-trialUsername=>$membershipUsername,
-trialPassword=>$membershipPassword
);
}
}
}
}
# 로그아웃은 로그인 여부와 무관하게 수행된다.
# membershipUsername이라 이름붙인 세션 변수에
# 사용자 이름을 기록한다.
$objectSession->param("membershipUsername", "<undefined>");
# membershipPassword이라 이름붙인 세션 변수에
# 사용자 암호를 기록한다.
$objectSession->param("membershipPassword", "<undefined>");
# 세션 객체를 삭제함
$objectSession->delete();
# 클라이언트에도 이미 삭제된 세션 ID가 남아있지 않도록 쿠키를 강제 만료
$objectCookie = new CGI::Cookie
(
-name=>"CGISESSID",
-value=>"under",
-expires=>"-12h"
);
# 쿠키는 HTTP 헤더 부분에 명시되어야 하므로 웹 페이지의 본문에 앞서 이를 출력함
print "Set-Cookie: ", $objectCookie->as_string, "\n";
print "Content-type: text/html; charset=UTF-8\n\n";
################################################################################
# 웹 페이지 본문 영역
print "<!DOCTYPE html>";
print "<html lang='ko'>";
print "<head>";
print "<meta charset='UTF-8' />";
print "<title>4 단계 : 로그아웃</title>";
print "<style>a { color: #0000FF; }</style>";
print "</head>";
print "<body>";
print "<header>";
print "<h1>4 단계 : 로그아웃</h1>";
print "</header>";
print "<hr />";
print "<section>";
if ($authorizeStatus)
{
# 로그인 된 상태였다면...
print "<p>로그아웃되었습니다.</p>";
print "<p><a href='./step1.cgi'>로그인</a></p>";
}
else
{
# 로그인 안 된 상태였다면...
print "<p>로그인되어있지 않습니다.</p>";
print "<p><a href='./step1.cgi'>로그인</a></p>";
}
print "</section>";
print "<hr />";
print "<footer>";
print "<p>";
print "<a href='./step1.cgi'>1 단계(로그인)</a> |";
print "<a href='./step2.cgi'>2 단계(사용자 인증)</a> | ";
print "<a href='./step3.cgi'>3 단계(회원 페이지)</a> | ";
print "<strong>4 단계(로그아웃)</string>";
print "</p>";
print "</footer>";
print "</body>";
print "</html>";

본 소스 코드의 실행 결과 서버에 보관되어있던 세션도 삭제되었음을 확인할 수 있다.

step1.cgi - 중복 로그인을 방지하기 위한 소스 코드의 수정
앞서 작성한 step3.cgi을 살펴보면, 세션으로부터 사용자 이름과 암호를 읽은 후 로그인 유효성을 재검증하는 부분이 있다. 로그인이 재차 승인되면 쿠키의 유효기간이 연장되면서 회원 전용 페이지를 보여주고 그렇지 않으면 로그인 화면으로 안내하는 메시지를 보여주는데 이를 step1.cgi에 적용해본다. 중복 로그인을 방지하기 위해 쿠키를 읽어들이고 이미 로그인이 유효한 상태라면 곧바로 회원 페이지로 넘어갈 수 있도록 안내하는 기능이 추가된다.
#!/usr/bin/perl
use CGI qw/:standard/;
use CGI::Cookie;
################################################################################
# 사용자 인증 로직
# 이름과 암호를 비교하며 승인되면 nonzero, 승인 안 되면 zero를 반환한다.
# 아래 이름의 사용자면 로그인 승인 함.
my $authorizedUsername = "codingCat";
# 아래의 암호를 입력하면 로그인 승인 함.
my $authorizedPassword = "qwerty123456!";
# 로그인 승인 시 nonzero, 아니면 zero
my $authorizeStatus = 0;
# authorizeMembership(-trialUsername, -trialPassword)
# 사용자 이름과 암호를 비교하여 로그인 승인 여부를 결정하는 서브루틴.
# -trialUsername : 로그인을 시도하는 사용자 이름
# -trialPassword : 로그인을 시도하는 사용자가 입력한 암호
# 로그인 승인하면 nonzero를 반환하고 승인 거부 시 zero를 반환한다.
sub authorizeMembership(@)
{
my %args = @_;
my $trialUsername = $args{"-trialUsername"};
my $trialPassword = $args{"-trialPassword"};
# 로그인 요청하는 사용자 이름이 미리 지정된 이름과 같은지 검사
if ($trialUsername eq $authorizedUsername)
{
# 이름이 일치하면, 암호가 같은지 검사
if ($trialPassword eq $authorizedPassword)
{
# 이름과 암호가 모두 일치하면 로그인 승인
return 1;
}
}
# 그렇지 않을 경우 로그인 거부
return 0;
}
################################################################################
# 웹 페이지 헤더 영역
# 세션에 기록된 사용자 이름 및 암호를 읽어와서 로그인 유효성을 검증한다.
$membershipUsername = undef;
$membershipPassword = undef;
# CGI 객체를 생성한다.
$objectCGI = new CGI;
# 본 페이지로 전달된 쿠키를 확인한다.
%objectCookies = fetch CGI::Cookie;
# 쿠키가 존재하면
# 로그인 유효성 검사 : 클라이언트의 쿠키가 본 페이지에 전달한 로그인 정보를 검증한다.
if (%objectCookies ne undef)
{
# 쿠키 변수 중 CGISESSID라는 데이터가 있는지 확인
if ($objectCookies{"CGISESSID"} ne undef)
{
# CGISESSID가 있으면 세션 객체를 불러온다.
$objectSession = new CGI::Session
(
undef,
(scalar $objectCookies{"CGISESSID"}->value),
{Directory=>"/tmp"}
);
# 세션 변수 중 membershipUsername이라는 데이터가 있는지 확인
if ($objectSession->param("membershipUsername") ne undef)
{
# membershipUsername이 존재하면, membershipPassword라는 데이터도 있는지 확인
if ($objectSession->param("membershipPassword") ne undef)
{
# 세션 변수에서 얻은 사용자 이름과 암호로 로그인 상태가 유효한지 검증
$membershipUsername = $objectSession->param("membershipUsername");
$membershipPassword = $objectSession->param("membershipPassword");
# membershipUsername과 membershipPassword가 모두 수신되면,
# 앞서 정의된 authorizeMembership 메서드로 로그인 요청한다.
$authorizeStatus = authorizeMembership
(
-trialUsername=>$membershipUsername,
-trialPassword=>$membershipPassword
);
}
}
}
}
# 로그인 요청이 승인되었다면
if ($authorizeStatus)
{
# membershipUsername이라 이름붙인 세션 변수에
# 사용자 이름을 기록한다.
$objectSession->param("membershipUsername", $membershipUsername);
# membershipPassword이라 이름붙인 세션 변수에
# 사용자 암호를 기록한다.
$objectSession->param("membershipPassword", $membershipPassword);
# 세션의 유효 기간은 현재 시점으로부터 12시간이다.
$objectSession->expire("+12h");
# 현재의 편집 상태를 세션으로 저장한다.
$objectSession->flush();
# 세션을 생성할 때 발급된 세션 ID를 CGISESSID라는 쿠키 변수로써 클라이언트에 전달한다.
# 여기에서는 쿠키의 유효 기간도 세션과 마찬가지로 12시간으로 정한다.
$objectCookie = new CGI::Cookie
(
-name=>"CGISESSID",
-value=>($objectSession->id),
-expires=>"+12h"
);
# 쿠키는 HTTP 헤더 부분에 명시되어야 하므로 웹 페이지의 본문에 앞서 이를 출력함
print "Set-Cookie: ", $objectCookie->as_string, "\n";
}
print "Content-type: text/html; charset=UTF-8\n\n";
################################################################################
# 웹 페이지 본문 영역
print "<!DOCTYPE html>";
print "<html lang='ko'>";
print "<head>";
print "<meta charset='UTF-8' />";
print "<title>1 단계 : 로그인</title>";
print "<style>a { color: #0000FF; }</style>";
print "</head>";
print "<body>";
print "<header>";
print "<h1>1 단계 : 로그인</h1>";
print "</header>";
print "<hr />";
print "<section>";
if ($authorizeStatus)
{
# 로그인 승인 되었다면...
print "<p>이미 로그인되어 있습니다.</p>";
print "<p><a href='step3.cgi'>회원 페이지</a></p>";
}
else
{
# 로그인 거부 되었다면...
print "<p>사용자 이름과 사용자 암호를 입력하세요.</p>";
print "<form action='./step2.cgi' method='post'>";
print "<label for='trialUsername'>사용자 이름 : </label><input type='text' id='trialUsername' name='trialUsername' />";
print "<label for='trialPassword'>사용자 암호 : </label><input type='password' id='trialPassword' name='trialPassword' />";
print "<input type='submit' />";
print "</form>";
}
print "</section>";
print "<hr />";
print "<footer>";
print "<p>";
print "<span><a href='./step1.cgi'>1 단계(로그인)</a> | </span>";
print "<span><strong>2 단계(사용자 인증)</strong> | </span>";
print "<span><a href='./step3.cgi'>3 단계(회원 페이지)</a> | </span>";
print "<span><a href='./step4.cgi'>4 단계(로그아웃)</a></span>";
print "</p>";
print "</footer>";
print "</body>";
print "</html>";