본 게시글은 How To: Pass Data Between View Controllers in Swift를 바탕으로 작성하였습니다.
여러분의 앱이 여러 개의 사용자 인터페이스(UI)를 가지고 있다면 여러분은 하나의 UI에서 다른 UI로 데이터를 전달해야 하는 경우도 생길 것입니다. Swift에서는 View Controller 사이에 어떤 방법으로 데이터를 전달할 수 있을까요?
뷰 컨트롤러(View Controller) 사이에 데이터를 주고 받는 것은 iOS 개발의 중요한 일부입니다. 여러분은 몇 가지 방법으로 이를 해낼 수 있고 각기 다른 이점과 약점을 가지고 있습니다.
뷰 컨트롤러 사이에 쉽게 데이터를 교환하는 방법을 선택하는 것은 여러분이 앱 구조를 어떻게 할 것인지에 달려 있습니다. 앱의 구조(App architecture)는 여러분이 뷰 컨트롤러 사이에 어떻게 작동이 이루어 질 것인지에 영향을 주고, 반대로 여러분이 뷰 컨트롤러 사이에 데이터 교환을 어떻게 할 것인지에 따라 앱의 구조가 달라집니다.
Swift에서 여러분은 뷰 컨트롤러 사이에 다음의 6가지 방법으로써 데이터를 주고 받을 수 있습니다.
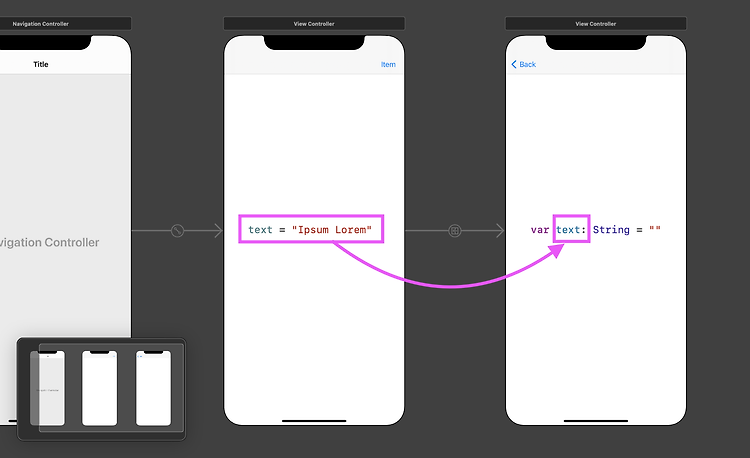
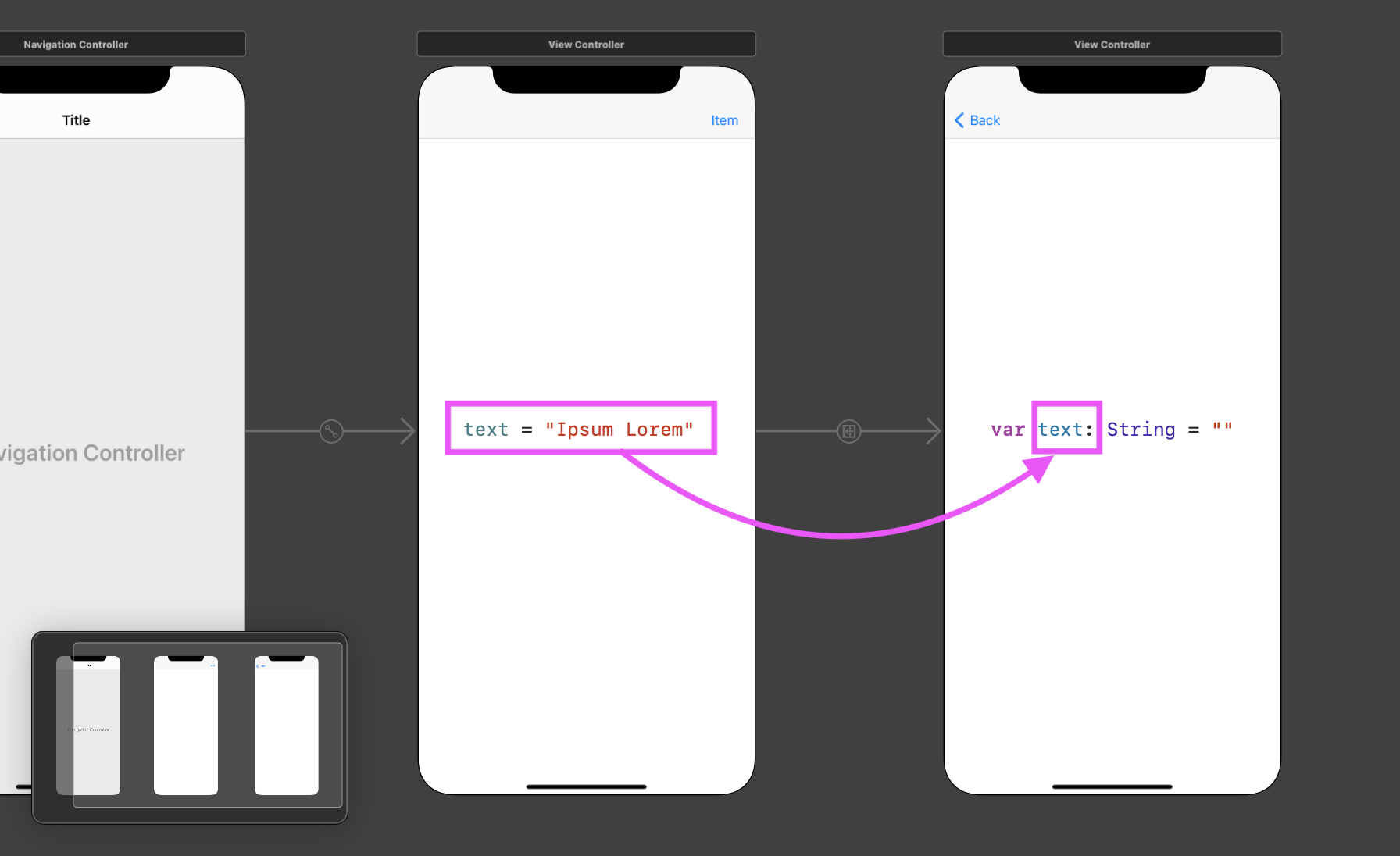
- 인스턴스 프로퍼티(property)를 사용하는 방법(A → B 방향)
- 스토리보드(Storyboard)와 세그웨(segue)를 사용하는 방법
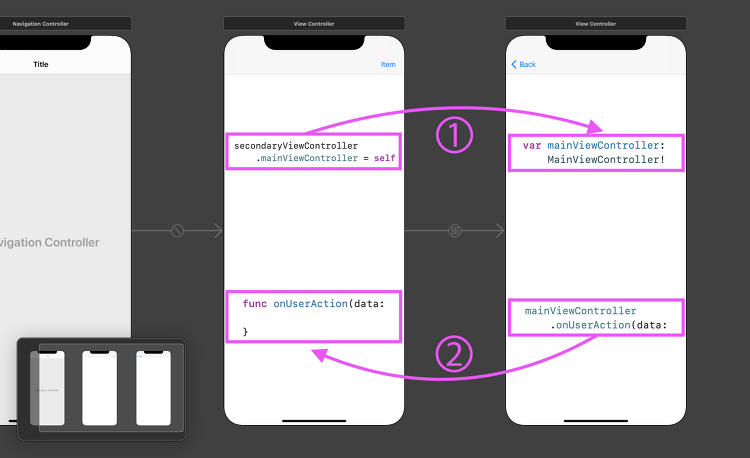
- 인스턴스 프로퍼티와 함수를 사용하는 방법(A ← B 방향)
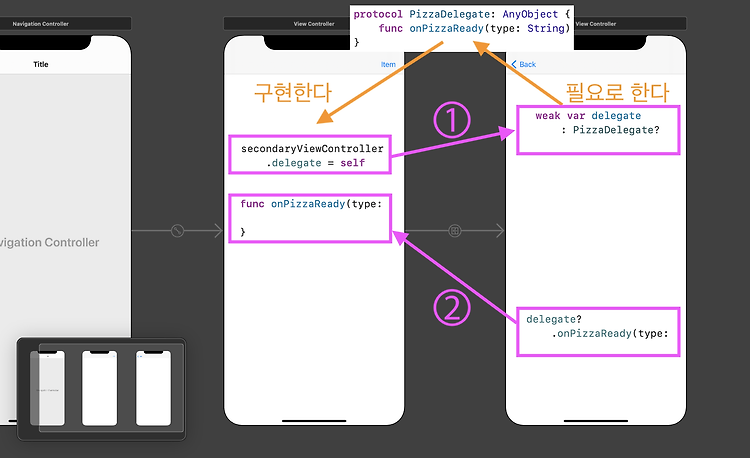
- 델리게이션(delegation) 패턴을 사용하는 방법
- 클로저(closure) 또는 핸들러(completion handler)를 사용하는 방법
- NotificationCenter 또는 Observer 패턴을 사용하는 방법
이 게시글에서 여러분은 뷰 컨트롤러 사이에 데이터를 주고 받는 6가지의 각기 다른 방법에 대해 익히게 될 것입니다. 이 방법에는 프로퍼티(property)를 사용하는 방법, 세그웨(segue)를 사용하는 방법 및 NSNotificationCenter를 사용하는 방법도 들어 있습니다. 비교적 간단한 이들 방법을 통해 좀 더 복잡한 응용까지 나아갈 수 있습니다. 준비가 되었다면 이제 시작하겠습니다.
스토리보드(Storyboard)와 세그웨(segue)를 사용하는 방법(A → B 방향)
스토리보드를 사용하고 있다면 여러분은 세그웨(segue)와 prepare(for:sender:) 메소드를 사용하여 뷰 컨트롤러 사이에 데이터를 전달할 수 있습니다.
스토리보드와 세그웨를 사용하여 뷰 컨트롤러 사이에 데이터를 전달하는 것은 앞서 XIB를 사용한 방법과 크게 다르지 않습니다. 스토리보드와 세그웨의 의미를 간단히 짚고 넘어가자면, 스토리보드는 여러분의 앱이 갖는 사용자 인터페이스들의 집합체입니다. Xcode의 Interface Builder를 가지고 생성할 수 있고 코드 작성을 최소화면서 뷰 컨트롤러 사이의 전환을 만들 수 있습니다.
세그웨(segue)는 부드러운 화면 전환(smooth transition)을 뜻합니다. 여러분이 예를 들어 내비게이션 컨트롤러를 가지고 어떤 뷰 컨트롤러에서 다른 뷰 컨트롤러로 전환시킬 때, 여러분은 이미 세그웨를 만든 것입니다. 여러분의 뷰 컨트롤러에서 이 세그웨에 후킹(hooking)하여 그 작동을 수정할 수도 있습니다. 뷰 컨트롤러 사이에서 발생하는 데이터 교환도 세그웨 과정 도중에 발생합니다.
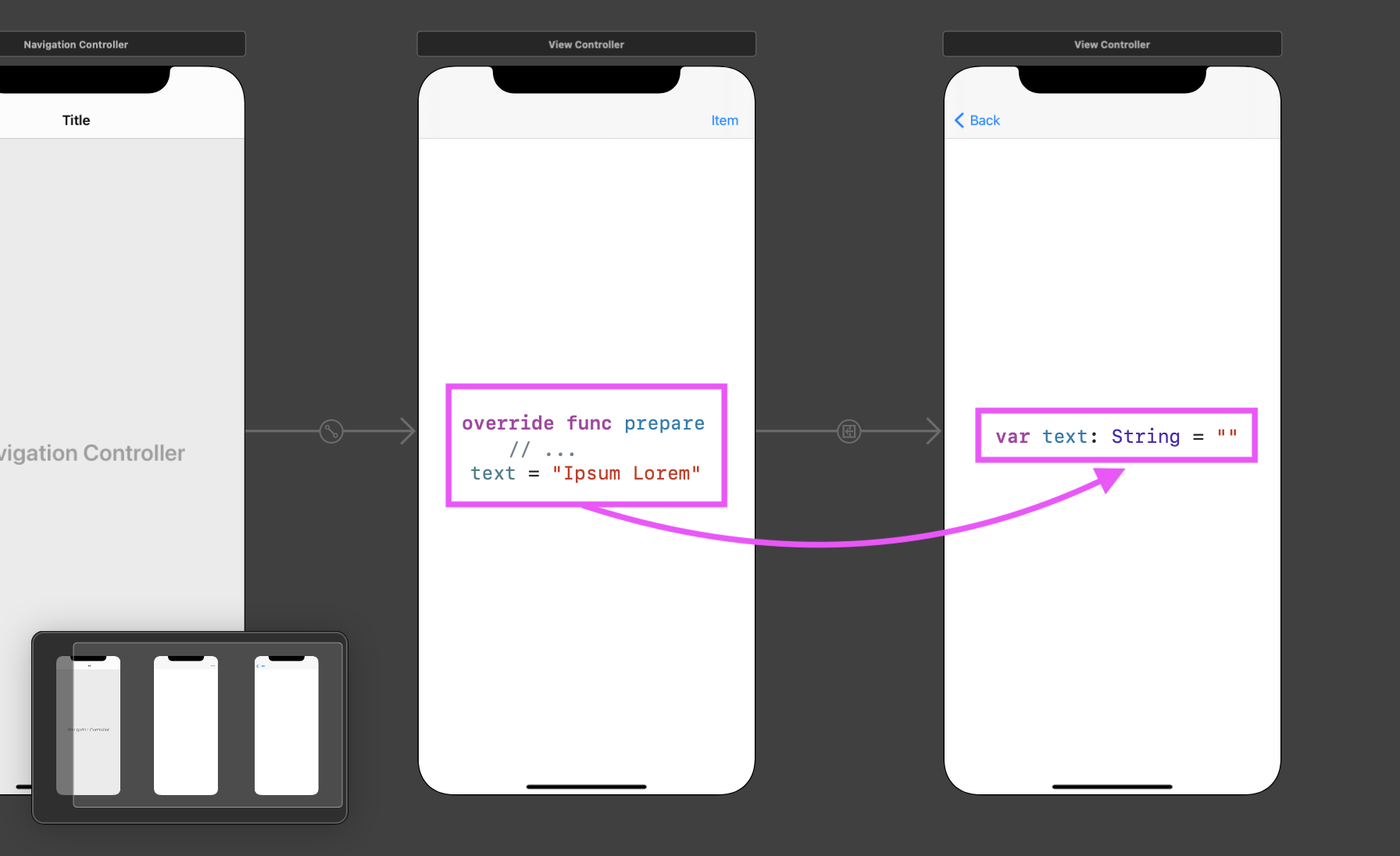
이번 예제에서 여러분은 MainViewController에서 TertiaryViewController로 전환되는 세그웨를 보게 될 것입니다. 이를 위해 어떤 액션을 한 버튼에서 다른 뷰 컨트롤러로 이어준 다음 "Show" 유형을 선택합니다. 그러면 MainViewController에서 TertiaryViewController로 이어지는 화살표가 나타날 것입니다. 그 다음 뷰 컨트롤러의 "Identity Inspector"에서 커스텀 클래스를 TertiaryViewController로 지정합니다.
TertiaryViewController의 코드는 다음과 같습니다.
// Swift
class TertiaryViewController: UIViewController {
var username: String = ""
@IBOutlet weak var usernameLabel: UILabel!
override func viewDidLoad() {
super.viewDidLoad()
usernameLabel.text = username
}
}// Objective-C
@interface TertiaryViewController: UIViewController {
@property (atomic, strong) NSString * username;
@property (nonatomic, weak) IBOutlet UILabel * usernameLabel;
@end
@implement TertiaryViewController
@synthesize username;
@synthesize usernameLabel;
-(void) viewDidLoad {
[super viewDidLoad];
[[self usernameLabel] setText: [self username]];
}
}
특별할 것도 없이 이 예제는 앞서 살펴보았던 것과 크게 다르지 않습니다. 여러분은 이 예제를 통해 usernameLabel이라는 라벨의 텍스트를 username이라는 프로퍼티가 현재 갖고 있는 문자열로 설정한 것일 뿐입니다.
이제 MainViewController에서 TertiaryViewController로 데이터를 전달해 보겠습니다. 이 때 prepare(for:sender:)라 불리는 특별한 메소드를 사용해야 하는데 이 메소드는 세그웨를 하기 전에 호출되는 메소드이므로 여러분은 이를 사용자화할 수 있습니다. 세그웨 직전 수행하게 될 코드는 다음과 같습니다.
// Swift
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
if (segue.destination is TertiaryViewController) {
let tertiaryViewController = segue.destination as? TertiaryViewController
tertiaryViewController.username = "Arthur Dent"
}
}// Objective-C
-(void) prepareForSegue:(UIStoryboardSegue *)segue sender:(id)sender {
if ([[segue destination] isKindOfClass: [TertiaryViewController class]]) {
TertiaryViewController * tertiaryViewController = (TertiaryViewController *)[segue destination];
[tertiaryViewController setUsername: @"Arthur Dent"];
}
}
위 코드에서 어떤 작업들이 수행되는지 살펴보겠습니다.
먼저 if문과 is 키워드는 세그웨의 목적지가 TertiaryViewController 클래스형인지를 검사하게 해 줍니다. 모든 세그웨는 이 prepare(for:sender:) 메소드를 거쳐가기 때문에 이 세그웨가 여러분이 사용자화하고 싶은 그 세그웨인지 아닌지를 검사할 필요가 있습니다.
그 다음 username 프로퍼티를 사용하기 위하여 segue.destination을 TertiaryViewController 클래스형으로 형변환합니다. segue 매개변수를 통해 전달되는 destination 프로퍼티는 UIViewController 형식으로 되어 있기 때문에 TertiaryViewController에서 선언한 username 프로퍼티를 사용하려면 이처럼 다운캐스트해야 합니다.
마지막으로 username 프로퍼티를 설정합니다. 이는 앞서 살펴 본 예제와 동일합니다.
prepare(for:sender:) 메소드에 대한 재미있는 사실은 여러분이 이 메소드에서 특정 세그웨 이외의 다른 것에 대해서는 작업할 필요가 없다는 것입니다. 이 메소드는 단순히 세그웨에 훅(hook)되기 때문에 화면 전환을 위해 이어서 나머지 작업을 수행하도록 어떤 코드들을 작성할 필요가 없다는 것입니다. 여러분은 여러분이 새로 구성한 뷰 컨트롤러를 반환할 필요도 없습니다.
또한 여러분은 위 Swift 코드를 다음과 같이 축약할 수도 있습니다.
// Swift
if let tertiaryViewController = segue.destination as? TertiaryViewController {
tertiaryViewController.username = "Ford Perfect"
}
destination의 타입을 검사하기 위해 is를 사용하고 캐스트하는 대신 옵셔널 캐스팅(optional casting)을 사용하여 한 문장으로 처리할 수도 있습니다. segue.destination이 TertiaryViewController 타입이 아니라면 as? 식은 nil을 반환할 것이고 조건문에 딸린 문장은 실행되지 않을 것입니다.
만일 형변환(type casting)을 사용하고 싶지 않다면 segue.identifier 프로퍼티로 특정 세그웨를 식별할 수도 있습니다. 예를 들어 스토리보드에서 이 프로퍼티에 "tertiaryVC"라는 문자열을 부여한 다음 다음과 같이 코드를 작성할 수도 있습니다.
// Swift
if segue.identifier == "tertiaryVC" {
// 수행할 작업
}// Objective-C
if ([[segue identifier] isEqualToString:@"tertiaryVC"]) {
// 수행할 작업
}
세그웨와 스토리보드를 사용하여 두 개의 뷰 컨트롤러 사이에 데이터를 전달하는 방법은 여기까지입니다.
대다수의 앱에서 스토리보드는 여러분이 사용할 수 있는 뷰 컨트롤러 사이의 전환을 제한합니다. 스토리보드는 종종 Xcode에서 사용자 인터페이스 만드는 것을 과도하게 복잡하게 만들기도 하는데 이에 비해 얻는 이점은 다소 적습니다. 무엇보다도 여러분이 복잡한 구조로 스토리보드나 XIB를 작성한다면 Interface Builder는 느려지고 버벅거립니다.
스토리보드로 작성할 수 있는 모든 것은 사실 여러분이 직접 손으로 코딩하여 구현할 수도 있습니다. 이 때는 개발자가 약간의 노력만 한다면 보다 상세한 제어가 가능합니다. 그렇다고 해서 필자는 여러분에게 손으로 일일이 다 코딩하라고 말하는 것은 아닙니다! 위의 예제처럼 하나의 뷰 컨트롤러당 하나의 XIB를 작성하고, UITableViewCell과 같은 서브 클래스 뷰(sub class view) 하나당 하나의 XIB를 작성합니다.
코더로서 궁극적으로 여러분은 탭 문자로 들여쓸 것인지 스페이스로 들여쓸 것인지, 스토리보드를 사용할 것인지 XIB를 사용할 것인지 아니면 Core Data를 쓸 것인지 Realm을 쓸 것인지 등등의 갈림길에서 여러분만의 최선의 선택을 찾고 싶어질 것입니다. 그것은 전적으로 여러분에게 달려 있습니다.
흥미로운 사실 모든 개발자들은 “segue”라는 단어를 자신만의 방법대로 발음하고 있습니다. 몇몇은 “se-” 부분을 “say”나 “set”의 “-e-”처럼 “-에-”로 발음하고, “-gue” 부분을 “gue_rilla”처럼 “-그웨”와 같이 발음합니다. 다른 이들은 “segway”처럼 “세그웨이”로 발음하기도 합니다. (segway: 여행자들을 위한 개인형 이동수단의 일종으로서 한 쌍의 바퀴로만 되어 있고 스스로 균형을 잡는 기구)