HLP 도움말은 Windows 3.1부터 Windows XP까지 지원하던 도움말 형식으로서, 내부적으로는 여러개의 RTF 문서 파일로 이루어져 있다. Windows Vista 이후에 출시되는 Windows 운영체제(Vista, 2008, 7, 2010, 8, 2012, 8.1, 10, ...)에서는 공식적으로 지원하지는 않는다. 이번 시리즈에서는 HLP 도움말을 제작하고, WinAPI에서 이를 불러오는 방법까지 알아보겠다.
준비물: 1. Windows XP 또는 그 이전 버전 운영체제, 2. Microsoft Word (아무 버전이나), 3. Microsoft Visual Studio 6.0
WinAPI에서 hlp 도움말 호출하기
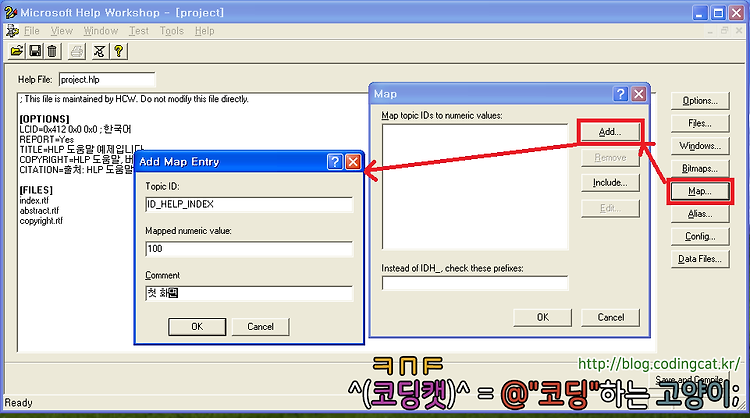
WinAPI에서 .hlp 파일 내의 내용을 띄워주기 위해서는 .hlp 파일을 구성하는 각 파일마다 프로그램적으로 구분 가능한 일련번호가 부여되어야 한다. 프로젝트 화면에서 [Map...] 버튼을 누른다. "Map" 대화상자가 뜨면 [Add...] 버튼을 눌러 "App Map Entry" 대화상자를 연다.
"Topic ID:"에는 .rtf 파일에서 '#' 각주로 지정한 문서의 ID를 적고, "Mapped numeric value:"에는 .hlp 파일 내에서 중복되지 않는 유일한 값을 임의로 부여한다. "Comment:"에는 간단한 설명을 붙일 수 있다.
프로젝트 화면에 [MAP] 항목이 새로 나타나면서 위에서 적었던 내용들이 나타난다면 컴파일한다.
여기서부터는 코딩이 시작된다. Visual C++를 실행한다. Win32 Application을 선택하여 새로 만든다.
소스 파일이 있는 경로와 출력 파일(.exe 파일)이 있는 경로에 각각 Help Workshop에서 만든 .cnt 파일과 .hlp 파일을 붙여넣는다.
WinAPI로 버튼을 하나 만든 다음, 버튼을 클릭 시 메시지를 처리하는 부분에서 아래의 함수를 호출해본다.
WinHelp(소유주가 되는 창의 핸들, TEXT(".hlp파일명"), HELP_CONTEXT, 보여줄 문서의 일련번호);
이 함수의 원형은 다음과 같다. 성공하면 TRUE를 반환하고 그렇지 않으면 FALSE를 반환한다.
HLP 도움말은 Windows 3.1부터 Windows XP까지 지원하던 도움말 형식으로서, 내부적으로는 여러개의 RTF 문서 파일로 이루어져 있다. Windows Vista 이후에 출시되는 Windows 운영체제(Vista, 2008, 7, 2010, 8, 2012, 8.1, 10, ...)에서는 공식적으로 지원하지는 않는다. 이번 시리즈에서는 HLP 도움말을 제작하고, WinAPI에서 이를 불러오는 방법까지 알아보겠다.
준비물: 1. Windows XP 또는 그 이전 버전 운영체제, 2. Microsoft Word (아무 버전이나), 3. Microsoft Visual Studio 6.0
일반 링크 만들기
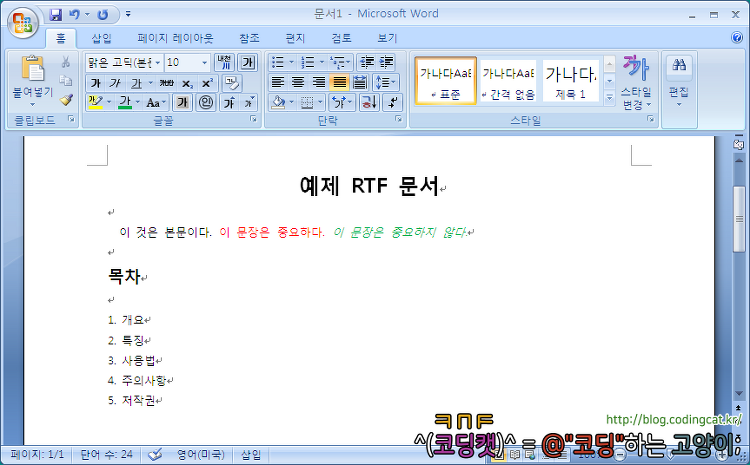
이번에는 도움말 본문에 링크를 만들어서 클릭하면 해당 문서로 이동하는 기능을 넣어보겠다. 먼저 도움말 파일의 개요를 보여 줄 예제 파일을 아래와 같이 작성한다.
파일 ID는 ID_HELP_ABSTRACT, 키워드는 '예제 도움말 파일의 개요 파일'로 지정한다.
파일명은 abstract, 파일형식은 서식 있는 텍스트(*.rtf)로 지정하여 저장한다.
이전 단계와 마찬가지로 [Files...] 버튼을 눌러 abstract.rtf 파일을 프로젝트에 추가한다.
색인 파일(project.cnt)도 함께 열어 이전 단계와 마찬가지로 abstract.rtf에 대한 항목을 추가한다.
도움말 생성 프로젝트에 파일 추가가 완료되면 index.rtf를 열어 링크를 삽입한다. 링크를 삽입하고 싶은 문단의 끝에 클릭 시 전환하게 될 문서의 ID를 "띄어쓰기 없이" 곧바로 적는다. 여기서는 클릭 시 ID_HELP_ABSTRACT의 ID가 붙은 문서가 보여져야 하므로 "1. 개요ID_HELP_ABSTRACT"와 같이 문단 끝에 곧바로 이 ID를 적어야 한다.
링크를 넣을 문구인 "1. 개요"까지만 선택한 후 마우스 오른쪽 버튼을 클릭한다. 다음 [단락(P)...] 메뉴를 클릭한다.
"효과" 영역 중 [취소선(K)] 버튼에 체크하여 선택한 문구가 "1. 개요"와 같이 취소선이 그어지게 설정한 다음 [확인] 버튼을 누른다.
이번에는 클릭 시 링크될 대상으로서 적은 ID_HELP_ABSTRACT에 대하여 블록을 지정하고 선택 후 마우스 오른쪽 버튼을 눌러 [단락(P)...] 메뉴를 클릭한다.
"효과" 영역 중 [숨김(H)] 버튼에 체크하고 [확인] 버튼을 누른다.
아래와 같이 ID가 사라지고, 링크할 텍스트에 취소선이 그어져있으면 된다.
숨겨진 텍스트로 된 링크 ID를 확인 또는 수정하고자 할 때는 [리본] 버튼 클릭 후 [Word 옵션(I)] 버튼을 클릭한다.
[표시] 버튼을 눌러 [숨겨진 텍스트(D)] 항목에 체크한 후 [확인] 버튼을 누른다.
아래와 같이 숨겨졌던 ID가 밑줄 표시된 채 보여질 것이다.
이제 프로젝트를 컴파일해보자. Help Workshop 컴파일러가 링크를 감지하여 "1 Jump"를 표시하는 것을 볼 수 있다.
.hlp 파일을 실행했을 때 취소선 서식을 넣었던 텍스트가 링크로 나타나는 것을 볼 수 있다.
이 링크를 클릭 시 해당 ID의 RTF 문서가 보여지고 [뒤로(B)] 버튼이 활성화 됨을 확인할 수 있다.
팝업 링크 만들기
이번에는 copyright.rtf 로 저작권 관련 내용을 적어서 도움말에 팝업 형태로 띄워보겠다. 예시 파일을 작성해본다.
'#' 각주에는 이 문서의 ID로 ID_HELP_COPYRIGHT를 부여하고, 'K' 각주에는 "이 예제 도움말 파일의 저작권"이라는 문구를 적어보겠다.
프로젝트로 가서 [Files...] 버튼을 눌러 copyright.rtf를 추가하고...
목차 파일에도 [Add Below...] 버튼을 눌러 저작권 항목을 추가한다.
링크를 삽입할 index.rtf를 열어 "5. 저작권" 글자 뒤에 띄어쓰기 없이 copyright.rtf의 ID인 ID_HELP_COPYRIGHT를 적는다.
링크를 넣을 텍스트만 블록을 설정한 후 마우스 오른쪽 버튼을 눌러 [글꼴(F)...] 메뉴를 클릭하고,
"밑줄 스타일(U):"의 옵션 중 실선을 클릭하여 평범한 밑줄을 넣는다. 그 다음 [확인] 버튼을 누른다.
마찬가지로 ID도 블록을 정해 글꼴 옵션에서 숨겨진 텍스트를 클릭한다.
아래와 같이 만들면 완성이다.
프로젝트로 돌아가 도움말 파일을 컴파일 해 본다. 앞서 만든 링크와 함께, Help Workshop 컴파일러가 두 개의 링크를 감지하여 "2 Jumps"가 뜨는 것을 볼 수 있다.
생성된 .hlp 파일을 실행하면 "5. 저작권"에 밑줄이 그어진 것을 볼 수 있다. 이를 클릭해보면...
아래와 같이 팝업 형태로 내용이 보여지게 된다.
Epilogue
다음 포스트에서는 만들어진 .hlp 파일을 이용해 WinAPI에서 불러올 수 있도록 해보겠다.
HLP 도움말은 Windows 3.1부터 Windows XP까지 지원하던 도움말 형식으로서, 내부적으로는 여러개의 RTF 문서 파일로 이루어져 있다. Windows Vista 이후에 출시되는 Windows 운영체제(Vista, 2008, 7, 2010, 8, 2012, 8.1, 10, ...)에서는 공식적으로 지원하지는 않는다. 이번 시리즈에서는 HLP 도움말을 제작하고, WinAPI에서 이를 불러오는 방법까지 알아보겠다.
준비물: 1. Windows XP 또는 그 이전 버전 운영체제, 2. Microsoft Word (아무 버전이나), 3. Microsoft Visual Studio 6.0
문서에 식별 ID 부여하기
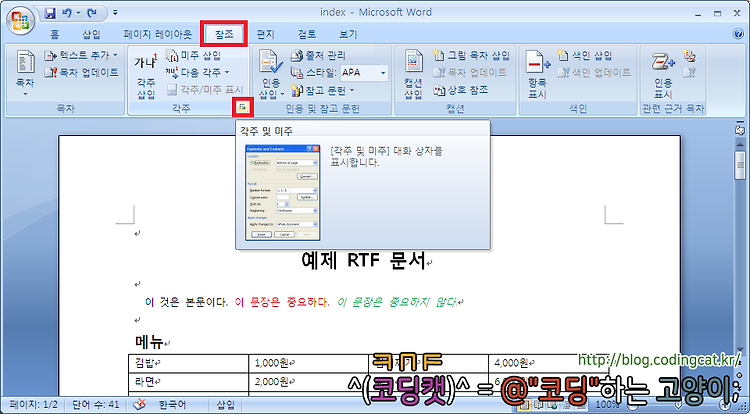
먼저, 각 문서별로 hlp 파일 내에서 식별할 수 있는 ID를 부여한다. [참조]-[각주] 카테고리 옆에 달린 작은 단추를 클릭한다.
[각주 및 미주] 대화상자가 뜬다. "위치"는 "각주(F):"를 선택하고, "서식"에는 "사용자 지정 표시(U):" 옆의 텍스트상자에 '#'을 입력한다. 그리고 [삽입(I)] 버튼을 누른다.
페이지 하단 각주 편집창으로 화면이 이동하는데, 여기에 이 문서의 고유 ID를 각자 알아서 지정하면 된다. 예를 들면, 이 문서에 ID_HELP_INDEX라는 ID를 부여할 수 있다.
Help Workshop으로 돌아가 우선 컴파일을 한다. 생성 결과에는 아직 아무런 차이도 보이지 않음을 확인할 수 있다.
문서에 색인 정보 추가하기
도움말의 '색인' 창을 통해 이 문서로 접근해오려면, 어떤 단어를 검색했을 때 이 문서가 나타나게 할 지를 지정하는 방법이 필요하다. 이를 위해 [참조]-[각주] 카테고리 옆에 달린 작은 단추를 다시 클릭하여 또 다른 각주를 추가한다.
이번에는 "사용자 지정 표시(U):" 텍스트 입력창에 Keyword의 약자인 'K'를 입력하고 [삽입(I)]를 클릭한다.
각주 편집으로 화면이 이동하면 이 페이지의 목적을 묘사할 수 있는 적절한 문구를 삽입한다.
Help Workshop에서 컴파일을 해 본다. 'K' 각주에 의해 아래 표시와 같이 "1 Keyword"가 뜸을 확인할 수 있다.
결과물을 확인한다. 전에는 비활성화 상태였던 [색인(I)] 단추가 활성화되어있음을 확인할 수 있다. 이를 클릭한다. [색인] 탭에서 'K' 각주에 적은 문구가 나타날 것이다.
목차 삽입하기
이번에는 목차를 삽입한다. Help Workshop 화면에서 [File]-[New] 메뉴를 클릭한다. 대화상자가 뜨면 [Help Contents]를 선택하고 [OK] 버튼을 누른다.
목차를 편집할 수 있는 화면으로 바뀌면서 새 목차 파일이 생성됨을 확인할 수 있다.
먼저 "Default filename (and window):" 칸에는 지금 컴파일에 의해 생성되고 있는 hlp 파일 이름을 적는다. "Default title:"에는 목차 및 색인 화면 상단 타이틀 바에서 보여질 제목을 적는다.
그 다음 [Add Above...] 버튼을 누른다. "Edit Contents Tab Entry" 대화상자가 뜬다. 대주제를 삽입하기 위해 Heading을 선택 후 "Title:" 텍스트박스에 대주제를 적는다. [OK] 버튼을 누른다.
아래와 같이 대주제가 삽입되었다.
소주제를 삽입하고 싶은 위치에 항목을 선택한 후 [Add Above] 또는 [Add Below]를 눌러 소주제를 삽입할 수 있다. 이 소주제가 우리가 작성하고 있는 RTF 파일로 연결될 것이다. "Edit Contents Tab Entry" 대화상자에서 Topic을 선택한 다음, "Title:"에는 소주제의 명칭을 적고, "Topic ID:"에는 RTF 파일에서 '#' 각주로 지정한 문서의 식별 ID를 적는다. 그리고 OK를 누른다.
아래와 같이 대주제 아래 소주제가 삽입되었음을 확인할 수 있다.
이제 이 목차를 저장한다. 파일명은 반드시 .hlp 파일과 같게 적고, 확장자는 .cnt여야 한다. 나중에 이 파일은 .hlp파일과 함께 배포되어야 한다.
목차 파일이 생성된 후에는 hlp 파일을 더블클릭하였을 때, RTF 문서의 내용이 그대로 출력되지 않고 아래와 같이 목차 및 색인 대화상자가 우선 뜨게 된다.
HLP 도움말은 Windows 3.1부터 Windows XP까지 지원하던 도움말 형식으로서, 내부적으로는 여러개의 RTF 문서 파일로 이루어져 있다. Windows Vista 이후에 출시되는 Windows 운영체제(Vista, 2008, 7, 2010, 8, 2012, 8.1, 10, ...)에서는 공식적으로 지원하지는 않는다. 이번 시리즈에서는 HLP 도움말을 제작하고, WinAPI에서 이를 불러오는 방법까지 알아보겠다.
준비물: 1. Windows XP 또는 그 이전 버전 운영체제, 2. Microsoft Word (아무 버전이나), 3. Microsoft Visual Studio 6.0
1. 미디어 삽입
이전 포스트에 이어서 이번에는 rtf 파일에 표와 그림을 삽입하여 도움말 파일을 제작한다.
1-1. 표 삽입
Microsoft Word의 [삽입]-[표]-[표] 메뉴를 클릭하여 표를 삽입한다.
아래와 같이 표에 적절한 내용을 채운다.
Help Workshop으로 돌아가 컴파일한 후 결과를 확인한다. 표의 테두리가 사라져 있음을 확인할 수 있다. hlp 형식의 도움말 파일은 표의 테두리 모양까지 지원하지는 않기 때문에 이렇게 보인다.
1-2. 그림 삽입
이번에는 그림을 삽입한다. 그림을 복사하여 워드에 직접 붙여넣기하면 된다. 일반적인 문서 작성과 다르지 않다.
만일 구 버전의 Microsoft Word(2007 버전 미만)를 사용중이라면 컴파일된 hlp 파일에서 이와 같이 붙여넣기로 삽입된 그림이 보이지 않을 수 있다. 이 때는 rtf 파일과 같은 폴더 안에 그림 파일을 생성한 후...
[삽입]-[일러스트레이션]-[그림] 메뉴를 클릭하여 그림 파일을 삽입한다.
컴파일한 hlp 결과이다.
Epilogue
이번 포스트에서는 매우 간단한 내용을 다루어보았다. 다음 포스트에서는 "색인과 목차" 기능에 대해 알아보겠다.
HLP 도움말은 Windows 3.1부터 Windows XP까지 지원하던 도움말 형식으로서, 내부적으로는 여러개의 RTF 문서 파일로 이루어져 있다. Windows Vista 이후에 출시되는 Windows 운영체제(Vista, 2008, 7, 2010, 8, 2012, 8.1, 10, ...)에서는 공식적으로 지원하지는 않는다. 이번 시리즈에서는 HLP 도움말을 제작하고, WinAPI에서 이를 불러오는 방법까지 알아보겠다.
준비물: 1. Windows XP 또는 그 이전 버전 운영체제, 2. Microsoft Word (아무 버전이나), 3. Microsoft Visual Studio 6.0
RTF 문서 준비하기
Microsoft Word를 켜고 아래와 같이 예제 문서를 작성해본다. 예제 문서니까 이것저것 서식도 마음대로 넣어보는 것이 가능하다.
저장할 때 파일 형식은 반드시 서식 있는 텍스트 또는 서식 있는 텍스트 (*.rtf)으로 지정한다.
HLP 문서 생성하기
[시작] 버튼-[모든 프로그램]-[Microsoft Visual Studio 6.0]-[Microsoft Visual Studio 6.0 도구들]-[Help Workshop]을 클릭한다.
프로젝트 생성하기
[File]-[New]를 눌러 [Help Project]를 선택한 후 [OK]를 누른다. 파일 저장 대화상자가 뜨면 적당한 경로에 프로젝트 파일 이름을 지정한 후 [저장(S)] 버튼을 누른다. 이 때, 확장자는 .hpj이다. 주의할 것은, 경로명에 한글이 들어갈 경우 hlp 파일이 제대로 생성되지 않을 수 있다는 것이다. 경로에 한글이 들어가지 않도록 주의해야 한다.
프로젝트 파일이 생성되며 화면이 아래와 같이 변한다. [Options...] 버튼을 누른다. 이 도움말 파일의 이름이나 내용 등을 적을 수 있는 부분이다.
'Help title:'에는 이 도움말 파일의 제목을 적는다. 'Copyright Information'에는 저작권 관련 문구를 적어넣을 수 있다. 'Display this text in the Version dialog box:'에는 버전 정보 대화상자에 보여줄 문구를 지정하고, 'If users paste or print Help text, display:'에는 사용자가 도움말의 일부를 복사/붙여넣기하거나 인쇄를 할 때 딸려오는 저작권 관련 문구를 적을 수 있다.
대화상자에 입력한 내용이 프로젝트 파일에 반영되었음을 확인할 수 있다.
이번에는 [Files...]를 누른다. 'Topic Files'이라는 대화상자는 이 도움말에 포함된 .rtf 파일들의 목록들을 보여주는 창인데, 아무것도 없으므로 [Add...]를 눌러 파일을 하나 추가한다.
프로젝트 컴파일
아래와 같이 Microsoft Word에서 작성했던 rtf 파일이 추가되었다. 우선 결과를 보기위해 우측 하단의 [Save and Compile] 버튼을 클릭한다.
아무 문제없이 .hlp 형식 도움말 파일이 생성완료 되었다면 hlp 파일의 경로가 뜨면서 생성 완료되었다는 메시지가 출력될 것이다.
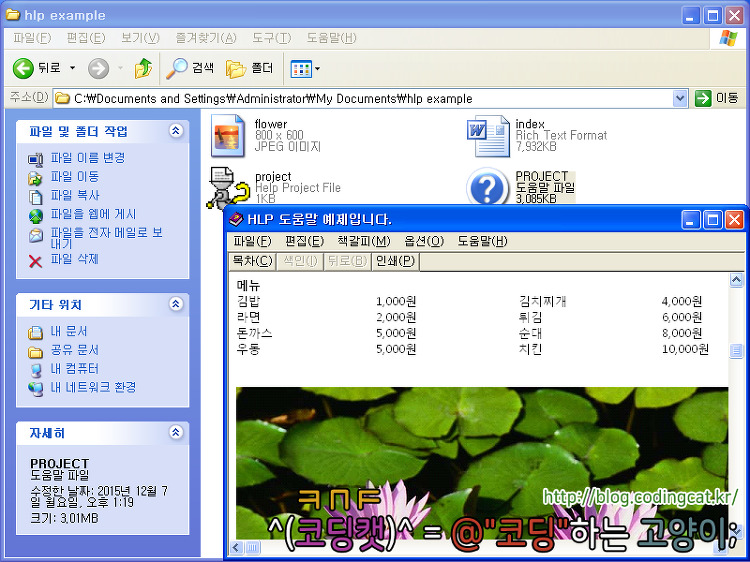
아래와 같이 .hlp 도움말 파일이 생성되었음을 확인할 수 있다. 더블클릭하여 열었을 때, Microsoft Word에서 작성했던 .rtf 파일과 같은 내용이 보인다면 성공한 것이다.
예제보니까 parameter에 void foo(int* const* bar) 이렇게 있더라고요;; 이게 definition으로서 가능해요? 만일 가능하다면 도대체 이렇게 정의하는 목적이 뭔지;; 그리고 만일 이게 된다면 const* int* bar도 되나요?? 답변 부탁드리겠습니다 ㅠ
그렇다면 값 변경이 안 되는 경우(어디서 값 변경이 안 되는가?)를 찾는 것이 관건이다. 질문 원문에서 소개 된 3가지 경우를 예로 들어보면,
const int ** foo;
int * const * foo;
int ** const foo;
이 3가지의 자료형이 있다. const가 붙는 위치가 조금씩 다름을 알 수 있는데 이 차이를 구분할 수 있다면 C의 고수이다.
위의 3가지 형식을 괄호로 쳐 본다면 다음과 같이 묶을 수 있다.
(const int) ** a;
(int * const) * a;
(int **) const a;
'const 자료형 **'의 해설
1번은 const int 형에 대한 이중 포인터이다. 즉 int형 상수에 대한 이중 포인터라는 뜻이다. 보다 쉽게 나타낸다면 이런 과정으로 만들어지는 타입이다.
{
const int a = 10;
const int * b = &x;
const int ** c = &y;
}
위와 같이 &b의 자료형이 const int ** 형이라 보면 된다. 알맹이 값인 a = 10이라는 값이 상수처리 되는 것이다.
반복하면,
{
c : const int ** 형 (값 변경 O)
*c : const int * 형 (값 변경 O)
**c : const int 형 (값 변경 X)
}
이므로,
int main(int argc, char * argv[]) {
const int a = 10;
const int * b = &a;
const int ** c = &b; // 이게 const int ** 형식임.
c = 0x00000000; // 대입시 에러 없음
*c = 0x00000000; // 대입시 에러 없음
**c = 5; // 여기서 에러.
return 0;
}
'자료형 * const *'의 해설
2번은 int * 형이 갖는 주소 값을 상수로 다룬다는 뜻이다. 즉 int *형 상수에 대한 포인터라는 뜻이다. 보다 쉽게 나타낸다면 이런 과정을 통해 만들어지는 타입이다.
{
int a = 10;
int * const b = &a;
int * const * c = &b;
}
위와 같이 &b의 자료형이 int * const * 형이라 보면 된다. 여기서 알맹이 값인 a = 10은 수정이 자유로우나, 이것이 위치한 주소(a의 주소)를 갖고 있는 b가 상수처리 되는 것이다.
반복하면,
{
c : int * const * 형 (값 변경 O)
*c : int * const 형 (값 변경 X)
**c : int 형 (값 변경 O)
}
이므로,
int main(int argc, char * argv[]) {
int a = 10;
int * const b = &a; // 여기서 &b가 100% 완벽한 int * const * 형을 갖게 된다.
int * const * c = &b; // 이게 int * const * 형이다.
c = 0x00000000; // 대입시 에러 없음
*c = 0x00000000; // 여기서 에러.
**c = 5; // 대입시 에러 없음
return 0;
}
'자료형 ** const'의 해설
3번은 int ** 타입 자체가 상수라는 뜻이다, 즉 이런 과정을 통해 만들어지는 타입이다.
{
int a = 10;
int * b = &a;
int ** const c = &b;
}
위와 같이 &b의 자료형을 상수로 처리하는 것이 int ** const 형이라 보면 된다.
{
c : int ** const 형 (값 변경 X)
*a : int * 형 (값 변경 O)
**a : int 형 (값 변경 O)
}
이므로,
int main(int argc, char * argv[]) {
int a = 10;
int * b = &a;
int ** const c = &b;
c = 0x00000000;// 여기서 에러.
*c = 0x00000000; // 대입시 에러 없음
**c = 5; // 대입시 에러 없음
return 0;
}
마무리
지식 iN에도 올렸지만, 다시 한번 표로 정리하면 아래와 같이 요약 가능하다.
선언된 형식
const int ** a
int * const * a
int ** const a
a의 형식
const int ** 형 (값 변경 O)
int * const * 형 (값 변경 O)
int ** const 형 (값 변경 X)
*a의 형식
const int * 형 (값 변경 O)
int * const 형 (값 변경 X)
int * 형 (값 변경 O)
**a의 형식
const int 형 (값 변경 X)
int 형 (값 변경 O)
int 형 (값 변경 O)
덧 1. 문자열 상수와 const
strcpy 같은 함수를 보면 두 번째 인수가 const char * 형으로 되어 있을 것이다. 풀이해 보면, 그 문자열의 주소는 경우에 따라 가변적이지만 문자열이 갖는 자체의 내용만큼은 변함이 없다. 이런 뜻이다.
문자열이 가리키는 주소 자체는 상수성이 없으므로 전혀 다른 문자열로 대치가 가능하다. 그러나 문자열의 내용에 대해서는 상수성이 있으므로 const char *로 선언된 문자열은 일부 내용의 수정이 불가하다.
덧 2. 멤버 함수와 const
C 언어에서 사용되는 const는 이 정도에서 끝나지만 C++로 넘어올 경우 하나가 더 있다. 멤버 함수의 scope에 붙이는 const 키워드이다.
class Integer {
private:
int value;
public:
int getInteger() const;
void setInteger(int value);
}
int Integer::getInteger() const {
return this->value;
}
void Integer::setInteger(int value) {
this->value = value;
}
위와 같이 멤버 함수의 scope에도 상수성을 부여할 수 있다. 이것의 의미는...
이 함수는 멤버 변수의 값을 읽을 수는 있어도 수정할 수는 없다.
이다. 만일,
int Integer::getInteger() const {
this->value = -1; // 오류 발생
return this->value;
}
위와 같은 코드를 실행한다면 const가 부여된 scope 내에서 멤버 변수의 수정을 시도하므로 오류가 발생할 것이다. 또한,
int Integer::getInteger() const {
this->setInteger(-1); // 오류 발생
return this->value;
}
또한 위와 같이 scope에 const 속성이 없는 다른 함수를 호출하는 것도 오류가 발생한다. 상수 함수에서 호출 가능한 멤버함수는 같은 상수 함수 뿐이다. 반대로 scope에 const가 없는 함수는 상수 함수이든 비 상수 함수이든 호출이 가능하다. 이렇게 선언하는 이유는 객체의 상수성 때문이다.
{
Integer i1;
const Integer i2;
i1.setInteger(-1); // 가능
i1.getInteger(); // 가능
i2.setInteger(-1); // 불가
i2.getInteger(); // 가능
}
객체 i1은 상수성이 없고, 객체 i2는 상수성이 있다. 상수성이 있는 객체는 멤버 변수의 수정이 불가능하므로 scope에 const가 명시된 멤버 함수만이 호출 가능하다. 따라서 i2.setInteger(-1);와 같은 호출은 불가능하다.
C 언어에서 문자열 처리는 복잡하다. 언어 수준에서 문자열이라는 데이터 형 자체를 지원하지도 않으니, 덧셈 기호(+)나 비교연산자(==)와 같은 기호를 사용하는 직관적인 문자열 연산을 사용할 수 없기 때문이다. C 언어가 문자열 데이터 형을 지원하지 않고, 문자열을 다루는 연산자도 없으니 모든 문자열 연산은 문자열 함수를 통해 이루어진다. C 표준 라이브러리(일명 'libc')에서 str...로 시작하는 함수들이 그것이며, 모두 string.h 헤더(C++은 cstring 헤더)에 정의되어 있으며 본 시리즈를 통해 이들 함수의 사용법을 정리해보고자 한다. 본 시리즈는 cplusplus(http://www.cplusplus.com) 및 MSDN에 나와있는 레퍼런스를 기준으로 하여 작성되었다.
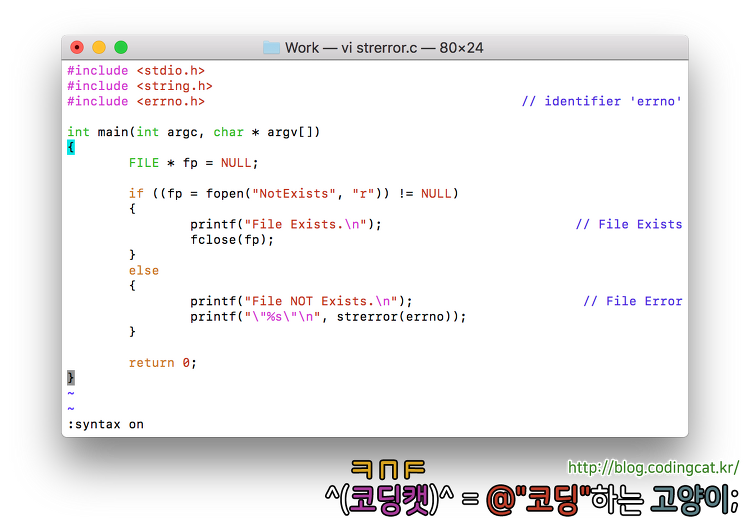
[그림 1] strerror.c 예제 소스 코드[그림 2] strerror.c 예제 소스 코드의 실행 결과
존재 하지 않는 이름("NotExists")의 파일을 fopen 함수를 통해 열려고 하였다. 당연히 fopen 함수는 NULL을 반환하지만 한편으로는 전역변수 errno에 오류 코드를 설정한다. 이 오류 코드는 정수(int)형인데 구체적으로 사용자가 읽을 수 있는 텍스트로써 어떤 내용인지를 보고자 할 때 strerror 함수를 사용하여 문자열 형태로 출력하고 있음을 확인할 수 있다.
1-1. Wide Character 확장 함수 - _wcserror
현재 버전의 표준 C 라이브러리에는 wchar 버전의 strerror 함수가 정의되어 있지 않다. Visual Studio 사용자는 UTF-16/UTF-32와 같은 Wide Character 문자열 형식에 대해 위하여 다음의 함수를 사용 가능하다.
wchar_t * _wcserror(int errnum);
<Epilogue>
본 포스팅을 통해 문자열 비교 함수에 대해 정리해 보았다. 이것으로 C 표준 라이브러리(libc)에서 제공하는 문자열 조작 함수(strXXX)에 대한 정리를 모두 마친다.
C 언어에서 문자열 처리는 복잡하다. 언어 수준에서 문자열이라는 데이터 형 자체를 지원하지도 않으니, 덧셈 기호(+)나 비교연산자(==)와 같은 기호를 사용하는 직관적인 문자열 연산을 사용할 수 없기 때문이다. C 언어가 문자열 데이터 형을 지원하지 않고, 문자열을 다루는 연산자도 없으니 모든 문자열 연산은 문자열 함수를 통해 이루어진다. C 표준 라이브러리(일명 'libc')에서 str...로 시작하는 함수들이 그것이며, 모두 string.h 헤더(C++은 cstring 헤더)에 정의되어 있으며 본 시리즈를 통해 이들 함수의 사용법을 정리해보고자 한다. 본 시리즈는 cplusplus(http://www.cplusplus.com) 및 MSDN에 나와있는 레퍼런스를 기준으로 하여 작성되었다.
이번 포스팅에서는 시스템 로케일 설정에 따라 문자열을 변환하고 비교할 목적으로 사용되는 함수인 strxfrm과 strcoll 함수에 대해 정리한다.
1. strxfrm
strxfrm 함수는 시스템 로케일 설정에 따라 문자열을 변환transform하여 버퍼에 복사하고 변환된 문자열의 길이를 반환하는 함수이다. 여기서 변환이란 시스템 로케일에서 정의한 문자열 변환작업을 의미하는데 구체적으로 무엇을 어떻게 변환하는지에 대해서는 명확하게 정의된 것이 없다. 다만, 변환된 문자열은 일종의 해시hash로서 취급되며 strcmp 함수에 의한 일치 또는 순서가 본래의 문자열과 일치함은 보장한다.
함수의 수행 결과 현재 시스템 로케일 조건에서 원본 문자열로부터 변환된 문자열이 destination으로 지정한 문자열 버퍼에 복사되고 이 버퍼에 복사된 문자 수가 반환된다.
다음은 strxfrm 함수의 사용 예이다. macOS(10.13.6 High Sierra 기준) 및 FreeBSD에서는 로케일 기능을 구현하는 부분에서 버그가 존재하기 때문에 아래 소스 코드에 의한 결과가 다를 수 있다. 그 결과는 신뢰할 수 없으므로 가급적 macOS와 FreeBSD를 제외한 운영체제에서 실행해보기를 권장한다.
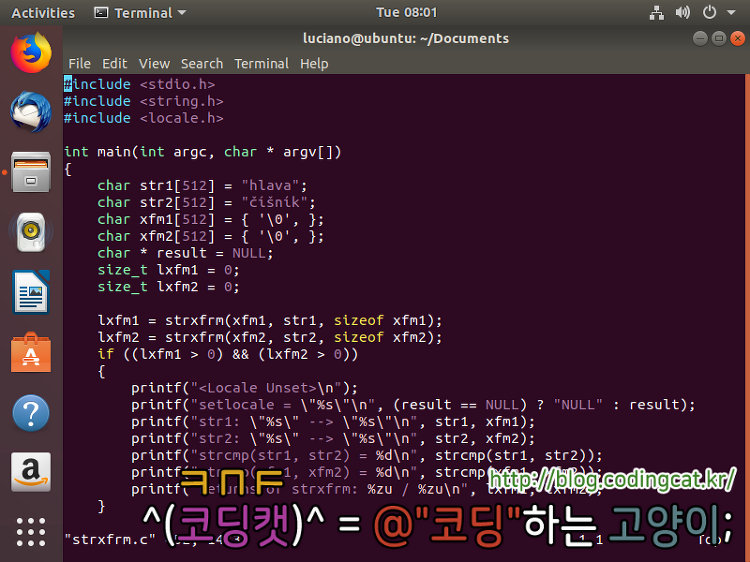
[그림 1] strxfrm.c 예제 소스 코드[그림 2] strxfrm.c 예제 소스 코드의 실행 결과
위 코드는 체코어 단어인 "hlava"와 "číšník"의 순서를 비교하는 예이다. 두 단어는 각각 str1과 str2에 UTF-8 인코딩으로 보관되어 있다. (단, unix 일때에 한함.) Microsoft Windows 등의 운영체제를 고려하여 확실하게 UTF-8 인코딩으로 문자열 상수를 보관하기 위해 str1와 str2의 상수 할당을 다음과 같이 지정해도 좋다.
보통의 소문자 'c'의 유니코드는 U+0063이고, 카론caron이 붙은 소문자 'č'의 유니코드는 U+010D이다. 또한 보통의 소문자 'h'의 유니코드는 U+0068이다. 유니코드에 의한 단순 정렬 시,
'c' (U+0063) - 'h' (U+0068) - 'č' (U+010D)
가 되겠지만 체코어 알파벳의 순서대로 문자를 정렬할 경우,
'c' (U+0063) - 'č' (U+010D) - 'h' (U+0068)
의 순서로 정렬된다. strxfrm은 특정 언어로 적힌 문자열을 strcmp로 순서 비교할 때 이러한 문화권(로케일) 차이를 반영하여 해당 언어의 사전 순서대로 정렬할 수 있도록 특별한 패턴의 문자열을 생성하는 역할을 한다. 다시 말하면, strcmp로 순서 비교하고자 할 때 여기에 들어갈 문자열은 "hlava"와 "číšník" 등의 원본 문자열이 아니고, strxfrm을 통해 변환된 문자열(일종의 해시hash)이어야 한다는 것이다.
첫 번째 실험인 <Locale Unset>항목을 본다.
아직 로케일을 명시하지 않은 상태이기 때문에 모든 문자열은 단순히 유니코드에 등재된 순서대로 비교 연산을 수행한다. 그렇기 때문에 strxfrm 함수는 문자열 버퍼에 원본 문자열 그대로를 복사하고 strcmp 함수는 원본 문자열 그대로 비교 연산을 수행한다. 앞서 설명한 대로 유니코드에 의한 단순 정렬 시 보통의 라틴문자인 'h'가 확장 라틴문자인 'č'에 선행하기 때문에(우선하기 때문에) strcmp("hlava", "číšník");의 결과 음수가 반환된다. strcmp의 반환값에 대한 설명은 [libc 문자열 조작 함수 정리 (part 03 - strcmp, strncmp)]를 참고한다.
두 번째 실험인 <cs_CZ.UTF-8>항목을 본다.
setlocale 함수를 사용하여 로케일이 설정된 상태이므로 체코어 알파벳 순서에 따라 문자열의 비교가 가능하다. 로케일이 설정된 상태에서 strxfrm 함수는 문자열 버퍼에 변환된 문자열을 만든다. 각 문자열은 "hlava"와 "číšník"로부터 얻어진 일종의 해시이기 때문에 읽을 수 있는 문자열은 아니지만 해당 문자열을 대신하여 strcmp 함수에 의한 우선순위 또는 일치 여부를 확인하는데 사용될 수 있다.
위와 같이 얻어진 문자열을 strcmp 함수에 적용해 보자. 로케일을 설정하기 전에는 'h'가 'č'에 선행한다고 보아 음수를 반환하였는데, 로케일을 설정한 후에는 'č'가 'h'에 선행한다고 보아서 양수를 반환하는 것을 볼 수 있다.
좀 더 확인하기 위하여 여러 종류의 로케일에 대해 문자열을 비교해보도록 한다. 위의 코드 중 setlocale에 전달되는 "cz_CS.UTF-8" 부분을 "문자열이 UTF-8로 인코드된 미국 영어 로케일"(en_US.UTF-8)과 "문자열이 UTF-8로 인코드된 한국어 로케일"(ko_KR.UTF-8)로 설정하였을 때 결과는 각각 다음과 같이 나올 것이다. (Ubuntu 기준)
미국 영어 로케일(en_US)도 체코어와 같은 로마자를 사용하므로 문자 'č'를 'c' 계열의 문자로 간주하여 'h'보다는 앞 순서로 판별하도록 strxfrm에서 문자열 변환이 이루어진다. 그러므로 strcmp(strxfrm("hlava"), strxfrm("číšník"));의 결과 양수가 반환된다.
한국어 로케일(ko_KR) 조건에서는 로마자 문화권이 아닌 상태가 되므로 'č' 문자를 인식하지 않아 단순 유니코드 값대로 순서가 판단되도록 strxfrm에서 문자열 변환이 일어나지 않는다. 그러므로 strcmp(strxfrm("hlava"), strxfrm("číšník"));의 결과 음수가 반환됨을 확인할 수 있다.
참고로 유닉스(리눅스)에서 현재 시스템이 지원 가능한 로케일의 목록을 확인하는 방법은 다음과 같다.
$ locale -a
로케일 관련된 파일들은 대체로 /usr/share/locale 디렉터리에 정의되어 있다. Debian(Ubuntu) 계열의 운영체제에서 특정 로케일을 설치하고자 할 경우 다음과 같이 실행한다.
예를 들어 한국어 로케일(ko-KR)을 생성하고자 할 경우,
$ sudo locale-gen ko_KR
그리고 EUC-KR 인코딩을 지원하는 한국어 로케일을 추가하고자 할 경우,
$ sudo locale-gen ko_KR.EUC-KR
1-1. Wide Character 확장 함수 - wcsxfrm
상기 strxfrm는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 복사는 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
int strcoll(const char * str1, const char * str2);
str1
현지 언어로 적힌 첫번째 문자열이다.
str2
현지 언어로 적힌 두번째 문자열이다.
strcoll 함수는 strxfrm 함수와 strcmp 함수를 합친 함수로서, 현재 설정된 로케일에 의한 문자열 비교 연산을 수행한다. 즉 변환 문자열을 담기 위한 버퍼의 선언과 변환 문자열의 복사는 함수 내부적으로 알아서 수행되므로 strcmp 함수를 사용할 때와 같은 방식으로 원본 문자열만 직접 전달해주면 비교 연산 결과를 반환한다. 문자열 비교 연산의 결과에 대한 정리는 [libc 문자열 조작 함수 정리 (part 03 - strcmp, strncmp)]를 참고한다.
앞서 예시로 적은 소스 코드를 strcoll 함수를 사용할 경우 다음과 같이 코드 분량을 줄이면서 현지 언어 문자열 비교를 할 수 있다.
[그림 3] strcoll.c 예제 소스 코드[그림 4] strcoll.c 예제 소스 코드의 실행 결과
마찬가지로 두 문자열에 대해 로케일을 적용하기 전의 문자열 비교 결과와 로케일 적용 후의 문자열 비교 결과가 서로 다름을 알 수 있다. 로케일을 적용하기 전에는 문자열을 단순 유니코드 순으로 정렬하므로 "hlava"가 "číšník"에 선행한다고 보아 음수를 반환하지만, 로케일을 적용한 후에는 확장 라틴 문자 또한 해당 언어의 알파벳 순서대로 비교하므로 "číšník"이 "hlava"에 선행한다고 보아 strcoll("hlava", "číšník");는 양수를 반환한다.
2-1. Wide Character 확장 함수 - wcscoll
상기 strcoll은 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 복사는 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
int wcscoll(const wchar_t * wcs1, const wchar_t * wcs2);
C 언어에서 문자열 처리는 복잡하다. 언어 수준에서 문자열이라는 데이터 형 자체를 지원하지도 않으니, 덧셈 기호(+)나 비교연산자(==)와 같은 기호를 사용하는 직관적인 문자열 연산을 사용할 수 없기 때문이다. C 언어가 문자열 데이터 형을 지원하지 않고, 문자열을 다루는 연산자도 없으니 모든 문자열 연산은 문자열 함수를 통해 이루어진다. C 표준 라이브러리(일명 'libc')에서 str...로 시작하는 함수들이 그것이며, 모두 string.h 헤더(C++은 cstring 헤더)에 정의되어 있으며 본 시리즈를 통해 이들 함수의 사용법을 정리해보고자 한다. 본 시리즈는 cplusplus(http://www.cplusplus.com) 및 MSDN에 나와있는 레퍼런스를 기준으로 하여 작성되었다.
/* strpbrk.c */
#include <stdio.h>
#include <string.h>
int main(int argc, char * argv[])
{
char str1[512] =
"L is for the way you look at me. "
"O is for the only one I see. "
"V is very, very extraordinary. "
"E is even more than anyone that you adore.";
char str2[] = "ELOV";
char * result = NULL;
printf("Original String: \n\"%s\"\n", str1);
printf("****************************************\n");
result = strpbrk(str1, str2);
while (result != NULL)
{
printf("\"%s\"\n", result);
result = strpbrk(result + 1, str2);
}
return 0;
}
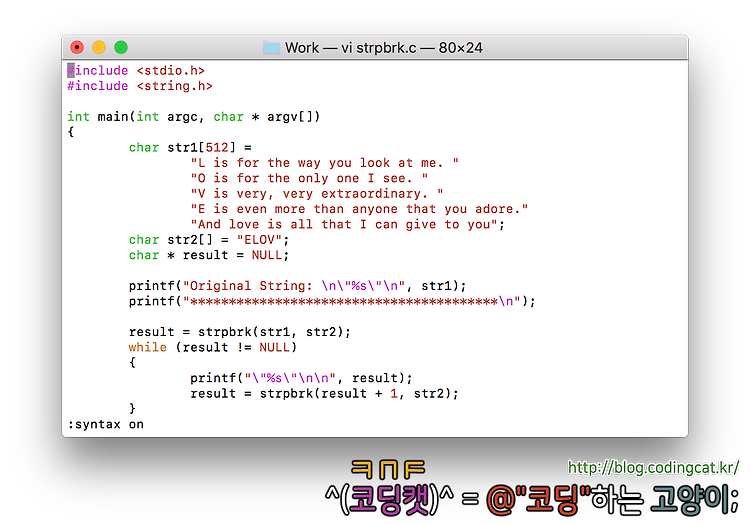
[그림 1] strpbrk.c 예제 소스 코드[그림 2] strpbrk.c 예제 소스 코드의 실행 결과
위 코드를 참조하면, 원본 문자열로부터 'E', 'L', 'O', 'V'로 시작하는 부분 문자열을 구하게 된다. 원본 문자열은 대문자로 시작하는 5개의 문장으로 구성되어 있고 이 문자열에 strpbrk를 적용하여 [그림 2]의 결과를 볼 수 있다. strpbrk의 두 번째 매개변수(str2)에는 'E', 'L', 'O', 'V'의 4개 문자만이 지정되어 있어 각 문자로 시작되는 부분 문자열을 얻을 수 있었지만, 'A'는 지정되지 않았으므로 마지막 문장은 출력되지 않음을 알 수 있다.
1-1. Wide Character 확장 함수 - wcspbrk
상기 strpbrk는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 복사는 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
C 언어에서 문자열 처리는 복잡하다. 언어 수준에서 문자열이라는 데이터 형 자체를 지원하지도 않으니, 덧셈 기호(+)나 비교연산자(==)와 같은 기호를 사용하는 직관적인 문자열 연산을 사용할 수 없기 때문이다. C 언어가 문자열 데이터 형을 지원하지 않고, 문자열을 다루는 연산자도 없으니 모든 문자열 연산은 문자열 함수를 통해 이루어진다. C 표준 라이브러리(일명 'libc')에서 str...로 시작하는 함수들이 그것이며, 모두 string.h 헤더(C++은 cstring 헤더)에 정의되어 있으며 본 시리즈를 통해 이들 함수의 사용법을 정리해보고자 한다. 본 시리즈는 cplusplus(http://www.cplusplus.com) 및 MSDN에 나와있는 레퍼런스를 기준으로 하여 작성되었다.
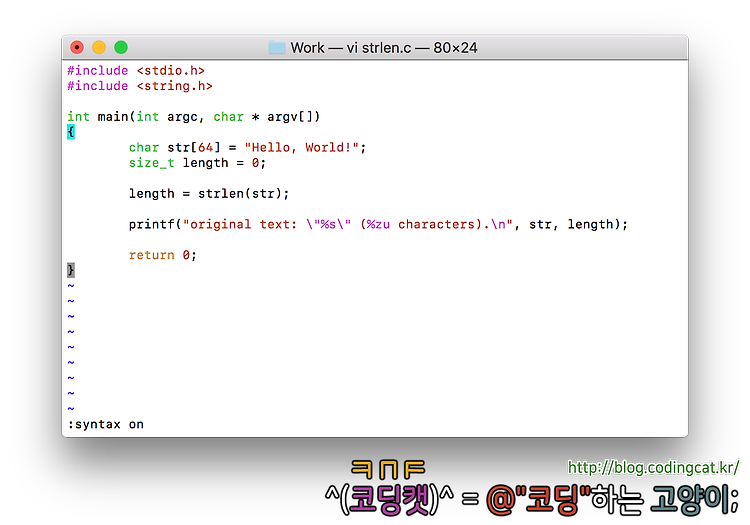
본 포스팅에서는 문자열의 길이length을 구하는 함수인 strlen 함수에 대해 정리한다.
<Prologue>
strlen은 C 스타일 문자열(맨 끝에 NULL ('\0')이 붙는 문자열)의 길이를 구하는 함수이다. 즉 NULL ('\0') 문자 직전의 문자까지만 센다. 예를 들어, 문자열 "Hello" = {'H', 'e', 'l', 'l', 'o', '\0'}의 경우 NULL ('\0') 문자를 제외한 5글자('H', 'e', 'l', 'l', 'o')만을 센다.
1. strlen
strlen의 원형은 다음과 같다.
size_t strlen(const char * str);
NULL문자를 만날때까지 문자를 하나씩 센다. 함수가 종료될 때 이 문자 수를 반환한다. 이 때 문자열 버퍼를 구성하는 NULL 문자는 개수에 포함되지 않는다. 메모리를 할당할 때 이를 고려하여 버퍼의 크기를 1개 문자 더 많게 설정해야 할 것이다.
[그림 1] strlen.c 예제 소스 코드[그림 2] strlen.c 예제 소스 코드의 실행 결과
2-1. Wide Character 확장 함수 - wcslen
상기 strlen는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 경우 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
C 언어에서 문자열 처리는 복잡하다. 언어 수준에서 문자열이라는 데이터 형 자체를 지원하지도 않으니, 덧셈 기호(+)나 비교연산자(==)와 같은 기호를 사용하는 직관적인 문자열 연산을 사용할 수 없기 때문이다. C 언어가 문자열 데이터 형을 지원하지 않고, 문자열을 다루는 연산자도 없으니 모든 문자열 연산은 문자열 함수를 통해 이루어진다. C 표준 라이브러리(일명 'libc')에서 str...로 시작하는 함수들이 그것이며, 모두 string.h 헤더(C++은 cstring 헤더)에 정의되어 있으며 본 시리즈를 통해 이들 함수의 사용법을 정리해보고자 한다. 본 시리즈는 cplusplus(http://www.cplusplus.com) 및 MSDN에 나와있는 레퍼런스를 기준으로 하여 작성되었다.
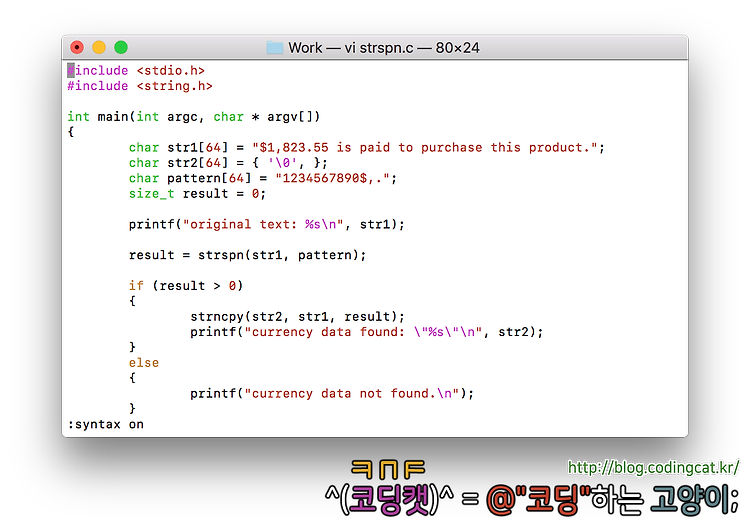
본 포스팅에서는 전체 문자열 중에서 특정 범위의 문자로만 구성된 부분 문자열span을 구하는 함수인 strspn과 strcspn 함수에 대해 정리한다.
<Prologue>
strspn은 문자열을 첫 글자부터 끝 글자까지 하나씩 탐색해 나가다가 미리 지정한 문자 외의 다른 문자를 만나면 지금까지 센 문자수를 반환하고 종료하는 기능을 한다. 즉 특정 범위의 문자로만 구성된 부분 문자열의 길이를 얻는 기능을 수행한다. 반대로 strcspn는 문자열을 첫 글자부터 끝 글자까지 하나씩 탐색해 나가다가 특정 범위의 문자로만 구성된 부분 문자열을 만났을 경우 그 위치를 반환한다.
반환 값은 size_t 형으로서, 맨 처음 문자부터 시작하여 str2에서 지정한 패턴을 벗어나지 않는 부분 문자열의 길이를 반환한다. 패턴에 맞는 부분 문자열이 처음부터 없다면 0을 반환한다.
예를 들어, 문장의 첫 부분에 금액이 적혀있는 경우 이를 인식하여 따로 보관하고자 한다. 금액은 '0'부터 '9'까지의 숫자 문자와 '.', ',', $ 기호로 구성되어 있기 때문에 이 범위를 벗어난 부분 문자열이 나타날때까지 문장의 첫 글자부터 세어 나가게 한다.
/* strspn.c */
#include <stdio.h>
#include <string.h>
int main(int argc, char * argv[])
{
char str1[64] = "$1,823.55 is paid to purchase this product.";
char str2[64] = { '\0', };
char pattern[64] = "1234567890$,.";
size_t result = 0;
printf("original text: %s\n", str1);
result = strspn(str1, pattern);
if (result > 0)
{
strncpy(str2, str1, result);
printf("currency data found: \"%s\"\n", str2);
}
else
{
printf("currency data not found.\n");
}
return 0;
}
[그림 1] strspn.c 예제 소스 코드[그림 2] strspn.c 예제 소스 코드의 실행 결과
위 코드를 참조하면, result = strspn(str1, pattern);에 의해 문자열의 맨 처음 문자로부터 주어진 패턴("123456789$,.")을 만족하는 부분 문자열의 길이를 얻는다. 이 값은 result 변수에 보관되며 구체적으로 9의 값("$1,823.55"의 총 9 문자)이 보관된다.
이 값은 strncpy 함수에서 사용된다. strncpy(str2, str1, result);에 의해 str1의 처음 9 문자가 str2에 복사된다. 즉, 해당 패턴을 만족하는 부분 문자열이 별도의 버퍼에 복사된 것이다. 이를 그 다음 줄인 printf 함수에서 출력하는 방식으로 본 예제는 작동한다.
1-1. Wide Character 확장 함수 - wcsspn
상기 strspn는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 경우 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
실행 결과 패턴을 만족하지 않는 부분 문자열의 길이, 다시 말하면 패턴을 만족하는 부분 문자열이 시작하는 위치를 반환한다. 만일 str1에는 str2에서 지정한 패턴에 맞는 부분 문자열이 없을 경우 str1의 길이를 반환한다.
상기 예제 코드에서 문자열을 수정하였다. 금액 관련한 표현이 문자열의 처음에 등장하지 않을 경우 해당 위치를 찾을 때 본 함수를 활용 가능하다.
/* strcspn.c */
#include <stdio.h>
#include <string.h>
int main(int argc, char * argv[])
{
char str1[64] = "Totol expense: $1,234.56 will be paid.";
char str2[64] = { '\0', };
char pattern[64] = "1234567890$,.";
size_t result = 0;
size_t count = 0;
printf("original text: \"%s\"\n", str1);
result = strcspn(str1, pattern);
if (result > 0)
{
printf("currency data found at %zu(th) position.\n", result);
count = strspn((str1 + result), pattern);
if (count > 0)
{
strncpy(str2, (str1 + result), count);
printf("currency data found: \"%s\"\n", str2);
}
else
{
printf("unexpected error.\n");
}
}
else
{
printf("currency data not found.\n");
}
return 0;
}
[그림 1] strcspn.c 예제 소스 코드[그림 2] strcspn.c 예제 소스 코드의 실행 결과
위 소스 코드를 참조하면, 찾고자 하는 패턴("1234567890$,.")의 숫자 문자열이 문장의 중간에 위치해 있는데 정확히 몇 번째 문자부터 시작하는지를 확인하기 위하여 strcspn을 사용한다. 이 함수는 해당 패턴이 만족하지 않는 부분 문자열의 길이를 반환하는데 이는 곧 해당 패턴이 만족하는 영역의 시작 위치이므로, result 변수에 보관한다. 구체적으로 이 값은 15, 즉 15번째 문자부터 해당 패턴을 만족하는 부분 문자열이 존재함을 알린다. (주의: C 언어는 맨 처음 문자를 0 번째로 본다.)
if 문의 조건(result > 0)을 만족하므로 상기 설명한 strspn 함수를 사용하여 검출하고자 하는 부분 문자열의 길이를 구한다. 이 때 매개변수로 전달되는 문자열 포인터는 str1 = &str[0]이 아니라 (str1 + result) = &str[15]임을 확인한다. strspn은 문자열의 중간에서 부분 문자열을 복사하는 기능이 없으므로 strcspn에서 구한 위치와 원본 문자열을 포인터 연산하여 해당 부분 문자열이 strspn의 입장에서 가장 처음에 오도록 전달하는 것이다.
패턴에 맞는 부분 문자열의 시작 위치를 strcspn을 통해 알고 있고 그 부분 문자열의 길이를 strspn을 통해 알았다면 복사만 하면 된다. 부분 문자열의 복사는 strncpy로 수행하는데 역시 복사 대상 문자열은 (str1 + result) = &str[15]으로 전달되었음을 확인한다.
2-1. Wide Character 확장 함수 - wcscspn
상기 strcspn는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 경우 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
C 언어에서 문자열 처리는 복잡하다. 언어 수준에서 문자열이라는 데이터 형 자체를 지원하지도 않으니, 덧셈 기호(+)나 비교연산자(==)와 같은 기호를 사용하는 직관적인 문자열 연산을 사용할 수 없기 때문이다. C 언어가 문자열 데이터 형을 지원하지 않고, 문자열을 다루는 연산자도 없으니 모든 문자열 연산은 문자열 함수를 통해 이루어진다. C 표준 라이브러리(일명 'libc')에서 str...로 시작하는 함수들이 그것이며, 모두 string.h 헤더(C++은 cstring 헤더)에 정의되어 있으며 본 시리즈를 통해 이들 함수의 사용법을 정리해보고자 한다. 본 시리즈는 cplusplus(http://www.cplusplus.com) 및 MSDN에 나와있는 레퍼런스를 기준으로 하여 작성되었다.
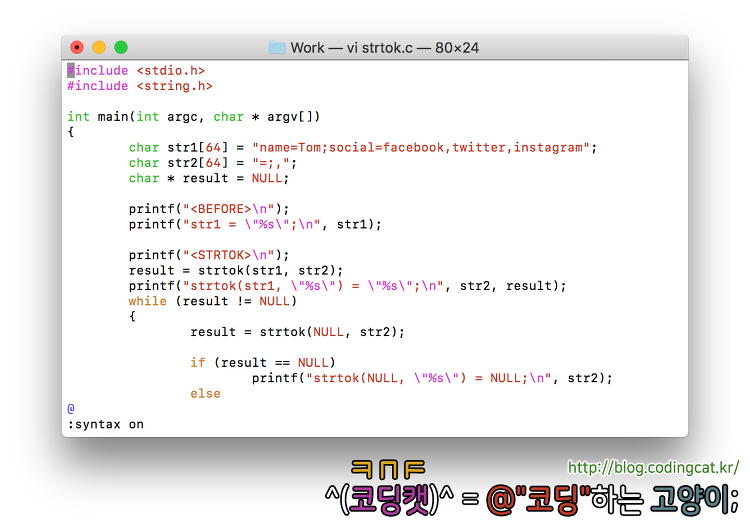
본 포스팅에서는 특정 기호를 기준으로 문자열 분할tokenization을 지원하는 함수인 strtok 계열의 함수에 대해 사용 예를 정리한다.
<Prologue>
strtok은 지정된 문자를 기준으로 문자열을 자르는 역할을 한다. 예를 들어 문자열 중에 ';' 문자가 있다면 그 문자 직전까지를 하나의 문자열로 보고, 그 문자 직후부터를 또 하나의 문자열로 취급한다는 뜻이다. 이 때 strtok 함수는 해당 문자열에서 ';' 문자가 있던 자리를 NULL 문자로 치환해버린다. 즉 원본 문자열의 내용이 변한다는 것이다.
구체적으로 "Rachel;Tom;John;Michael;Jude"라는 문자열에 대해 strtok 함수를 사용하여 ';' 문자를 기준으로 분할을 수행할 때 "Rachel", "Tom", "John", "Michael", "Jude"라는 5개의 부분 문자열을 얻는데, 이 과정에서 원본 문자열은 "Rachel\0Tom\0John\0Michael\0Jude"와 같이 원래 있던 ';' 문자가 NULL 문자로 변경된다.
[그림 1] strtok.c 예제 소스 코드[그림 2] strstr.c 예제 소스 코드의 실행 결과
위 코드는 "name=Tom;social=facebook,twitter,instagram"의 문자열을 strtok 함수로 분할하는 예이다. 해당 문자열은 세미콜론(';')과 등호('=') 및 컴마(',')로 단어들을 분리해낼 수 있음을 직관적으로 알 수 있다. C 언어로 이를 분리하기 위하여 deliminiters 매개변수에 세 기호들이 열거된 문자열을 전달한다.
분리 대상이 되는 문자열은 result = strtok(str1, str2);로서 최초 1회만 매개변수로 전달되고 그 이후 호출에서는 result = strtok(NULL, str2);와 같이 전달하지 않는다. 이미 대산 문자열을 한 번 분할했기 때문에 strtok 함수는 내부적으로 가장 마지막으로 분할한 위치를 기억하고 있기 때문이다. 만일 함수 호출 실행시마다 첫 번째 매개변수에 대상 문자열을 전달하면 분할 작업을 가장 첫 문자부터 시작하므로 최초로 분할되어 나온 부분 문자열만 반복하여 얻어질 것이다.
검색할 문자열의 끝에 도달하였거나 문자열에 분할 기준의 문자가 없어서 더 이상 분할될 수 없을 경우에는 NULL을 반환한다. 루프를 수행중이었다면 이 시점에 루프를 종료하면 된다.
1-1. Wide Character 확장 함수 - wcstok
상기 strtok는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 'tokenization'은 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
C 언어에서 문자열 처리는 복잡하다. 언어 수준에서 문자열이라는 데이터 형 자체를 지원하지도 않으니, 덧셈 기호(+)나 비교연산자(==)와 같은 기호를 사용하는 직관적인 문자열 연산을 사용할 수 없기 때문이다. C 언어가 문자열 데이터 형을 지원하지 않고, 문자열을 다루는 연산자도 없으니 모든 문자열 연산은 문자열 함수를 통해 이루어진다. C 표준 라이브러리(일명 'libc')에서 str...로 시작하는 함수들이 그것이며, 모두 string.h 헤더(C++은 cstring 헤더)에 정의되어 있으며 본 시리즈를 통해 이들 함수의 사용법을 정리해보고자 한다. 본 시리즈는 cplusplus(http://www.cplusplus.com) 및 MSDN에 나와있는 레퍼런스를 기준으로 하여 작성되었다.
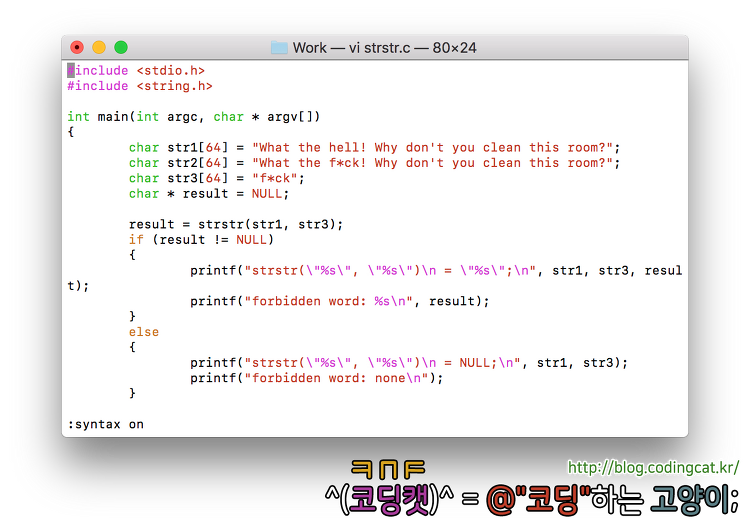
함수의 실행 결과 str2에서 지정한 문자열이 발견된 위치를 포인터로 반환한다. 그런 문구가 없으면 NULL이 반환된다.
다음은 strstr 함수의 실행 예이다.
/* strstr.c */
#include <stdio.h>
#include <string.h>
int main(int argc, char * argv[])
{
char str1[64] = "What the hell! Why don't you clean this room?";
char str2[64] = "What the f*ck! Why don't you clean this room?";
char str3[64] = "f*ck";
char * result = NULL;
result = strstr(str1, str3);
if (result != NULL)
{
// contains forbidden word
printf("strstr(\"%s\", \"%s\")\n = \"%s\";\n", str1, str3, result);
printf("forbidden word: %s\n", result);
}
else
{
// not contains forbidden word
printf("strstr(\"%s\", \"%s\")\n = NULL;\n", str1, str3);
printf("forbidden word: none\n");
}
printf("\n");
result = strstr(str2, str3);
if (result != NULL)
{
// contains forbidden word
printf("strstr(\"%s\", \"%s\")\n = \"%s\";\n", str2, str3, result);
printf("forbidden word: %s\n", result);
}
else
{
// not contains forbidden word
printf("strstr(\"%s\", \"%s\")\n = NULL;\n", str2, str3);
printf("forbidden word: none\n");
}
return 0;
}
[그림 1] strstr.c 예제 소스 코드[그림 2] strstr.c 예제 소스 코드의 실행 결과
위 코드를 참조하면, 검색 대상이 될 두 개의 문자열이 준비되어 있다. 하나는 "What the hell! Why don't you clean this room?"로서 욕설이 없는 문자열을 포함하는 str1이고, 다른 하나는 "What the f*ck! Why don't you clean this room?"로서 욕설이 있는 문자열을 포함하는 str2이다. 그리고 "f*ck"로서 검색할 욕 단어를 포함하는 str3가 준비되어 있다.
result = strstr(str1, str3);로서 str1에 대해 욕 단어가 있는지를 검색한다. 이 문자열에는 욕 단어가 포함되어 있지는 않으므로 NULL가 반환되며 result 포인터 변수에도 NULL이 보관된다.
result = strstr(str2, str3);로서 str2에 대해 욕 단어가 있는지를 검색한다. 이 문자열에는 str3에서 지정한 욕 단어가 포함되어 있으므로 해당 욕 단어가 시작되는 포인터가 반환되고 result 변수에 이 주소가 보관된다. 그러므로 printf로 이 변수를 출력하면 해당 욕으로 시작되는 부분 문자열이 출력되는 것이다.
1-1. Wide Character 확장 함수 - wcsstr
상기 strstr은 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 복사는 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
C 언어에서 문자열 처리는 복잡하다. 언어 수준에서 문자열이라는 데이터 형 자체를 지원하지도 않으니, 덧셈 기호(+)나 비교연산자(==)와 같은 기호를 사용하는 직관적인 문자열 연산을 사용할 수 없기 때문이다. C 언어가 문자열 데이터 형을 지원하지 않고, 문자열을 다루는 연산자도 없으니 모든 문자열 연산은 문자열 함수를 통해 이루어진다. C 표준 라이브러리(일명 'libc')에서 str...로 시작하는 함수들이 그것이며, 모두 string.h 헤더(C++은 cstring 헤더)에 정의되어 있으며 본 시리즈를 통해 이들 함수의 사용법을 정리해보고자 한다. 본 시리즈는 cplusplus(http://www.cplusplus.com) 및 MSDN에 나와있는 레퍼런스를 기준으로 하여 작성되었다.
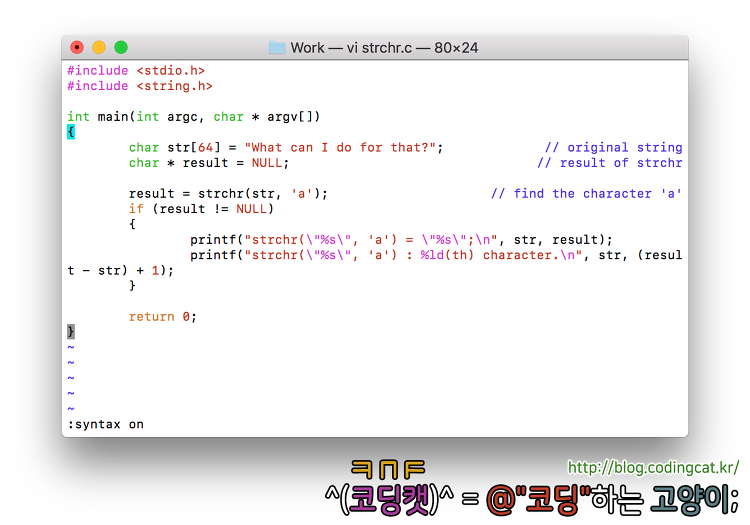
본 포스팅에서는 문자열로부터 특정 문자character의 검색을 지원하는 함수인 strchr 계열의 함수에 대해 사용 예를 정리한다.
<Prologue>
strchr와 strrchr는 문자열 중에서 특정 문자를 검색하여 그 위치를 얻는데 사용된다. 좀 더 엄밀히 말하면 그 문자가 시작되는 위치의 포인터를 반환한다. strchr은 문자열을 순방향으로 검색하여 가장 처음으로 발견될 때의 위치를 반환하고, strrchr은 문자열을 역방향으로 검색하여 가장 처음으로 발견될 때의 위치를 반환한다.
예를 들면 "What can I do for that?"라는 문자열에서 소문자 'a'로 시작되는 문자열을 얻고자 할 때,
strchr은 문자열을 첫 글자부터 순서대로 검색하여 ▶"What can I do for that?"와 같이 3번째에 있는 'a'를 검색하여 이 문자로 시작하는 문자열을 반환하고 strrchr은 문자열을 끝 글자부터 거꾸로 검색하여 "What can I do for that?"◀와 같이 맨 나중에 있는 'a'를 검색하여 이 문자로 시작하는 문자열을 반환한다.
1. strchr
C++ 라이브러리에서 제공하는 헤더 파일인 cstring에서는 검색 대상 문자열의 상수성 여부에 따라 2개의 함수가 오버로드overload되어 있다.
const char * strchr(const char * str, int character);
char * strchr(char * str, int character);
C 라이브러리에서 제공하는 헤더 파일인 string.h에서는 하나의 함수만이 정의되어 있다.
char * strchr(const char * str, int character);
str
검색 대상이 되는 문자열이다.
character
검색하고자 하는 특정 문자이다.
함수의 실행 결과 character의 문자로 시작하는 부분 문자열을 반환한다. 찾을 수 없으면 NULL을 반환한다.
원형을 자세히 보면 문자 매개변수 character가 char 형이 아닌 int 형으로 선언되어 있다. 참고로 char 형은 1 바이트, int 형은 CPU가 처리할 수 있는 기본 단위로 정의된다. 예를 들어 16 비트 CPU에서는 int가 2 바이트이고, 32 비트 CPU에서는 int가 4 바이트이며, 64 비트 CPU에서는 int가 8 바이트이다. C 언어에서 int보다 작은 크기의 데이터가 전달된다고 하더라도 CPU는 내부의 전자 회로 설계상 int 형으로 처리한다.
다음은 strchr의 사용 예이다.
/* strchr.c */
#include <stdio.h>
#include <string.h>
int main(int argc, char * argv[])
{
char str[64] = "What can I do for that?"; // original string
char * result = NULL; // result of strchr
result = strchr(str, 'a'); // find the character 'a'
if (result != NULL)
{
printf("strchr(\"%s\", 'a') = \"%s\";\n", str, result);
printf("strchr(\"%s\", 'a') : %ld(th) character.\n", str, (result - str) + 1);
}
return 0;
}
[그림 1] strchr.c 예제 소스 코드[그림 2] strchr.c 예제 소스 코드의 실행 결과
위 코드와 실행 결과를 참고하면, strchr(str, 'a');을 실행함으로써 대상 문자열의 3번째 위치한 'a'를 검색하였고 이 문자부터 시작하는 부분 문자열 "at can I do for that?"을 반환하였다. 반환된 문자열은 원본 문자열의 일부이므로 포인터간 뺄셈 연산을 사용하여 몇 번째 문자로서 검색되었는지를 확인할 수 있다. ((result - str) + 1)
1-1. Wide Character 확장 함수 - wcschr
상기 wcschr는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 검색은 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
strrchr 함수도 위의 strchr 함수와 동일하다. 다만, 검색 방향이 문자열의 맨 끝 문자부터 검색한다는 차이만이 있다. 함수의 원형은 다음과 같다.
C++ 헤더인 cwchar에는 상수성 여부에 따라,
const char * strrchr(const char * str, int character);
char * strrchr(char * str, int character);
C 헤더인 wchar.h에는,
char * strrchr(const char * str, int character);
str
검색 대상이 되는 문자열이다.
character
검색하고자 하는 특정 문자이다.
다음은 strrchr의 사용 예이다.
/* strrchr.c */
#include <stdio.h>
#include <string.h>
int main(int argc, char * argv[])
{
char str[64] = "What can I do for that?"; // original string
char * result = NULL;
result = strrchr(str, 'a'); // find the character 'a'
if (result != NULL)
{
printf("strrchr(\"%s\", 'a') = \"%s\";\n", str, result);
printf("strrchr(\"%s\", 'a') : %ld(th) character.\n", str, (result - str) + 1);
}
return 0;
}
[그림 3] strrchr.c 예제 소스 코드[그림 4] strrchr.c 예제 소스 코드의 실행 결과
[그림 2]와 [그림 4]의 실행결과를 비교해보면, result = strchr(str, 'a');을 실행 시 순방향으로 검색이 이루어지므로 최초 발견되는 문자는 3번째 문자인 'a'가 되어 "at can I do for that?" 문자열이 반환되지만 result = strrchr(str, 'a');을 실행 시 역방향으로 검색이 이루어지므로 최초 발견되는 문자는 21번째 문자인 'a'가 되어 "at?" 문자열이 반환됨을 알 수 있다.
2-1. Wide Character 확장 함수 - wcsrchr
상기 wcsrchr는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 검색은 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
C 언어에서 문자열 처리는 복잡하다. 언어 수준에서 문자열이라는 데이터 형 자체를 지원하지도 않으니, 덧셈 기호(+)나 비교연산자(==)와 같은 기호를 사용하는 직관적인 문자열 연산을 사용할 수 없기 때문이다. C 언어가 문자열 데이터 형을 지원하지 않고, 문자열을 다루는 연산자도 없으니 모든 문자열 연산은 문자열 함수를 통해 이루어진다. C 표준 라이브러리(일명 'libc')에서 str...로 시작하는 함수들이 그것이며, 모두 string.h 헤더(C++은 cstring 헤더)에 정의되어 있으며 본 시리즈를 통해 이들 함수의 사용법을 정리해보고자 한다. 본 시리즈는 cplusplus(http://www.cplusplus.com) 및 MSDN에 나와있는 레퍼런스를 기준으로 하여 작성되었다.
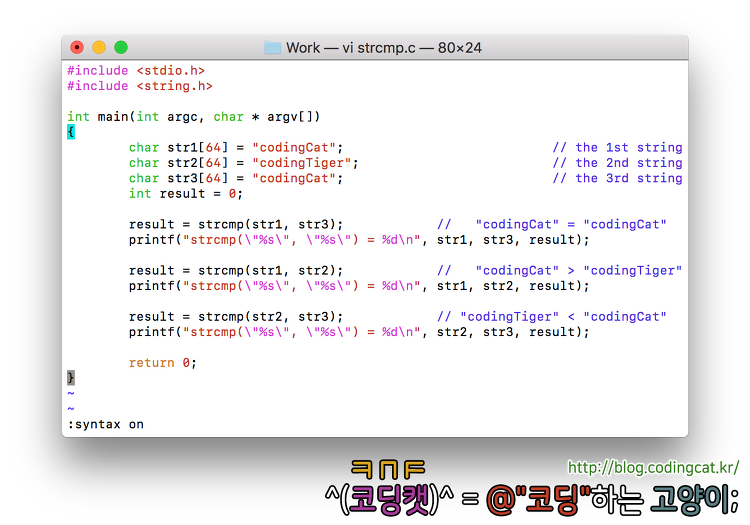
본 포스팅에서는 문자열 비교compare를 지원하는 함수인 strcmp 계열의 함수에 대해 사용 예를 정리한다.
<Prologue>
정수, 실수 등의 원시 자료형primitive data type에서는 두 변수간의 비교 연산자로 ==를 사용한다. 그러나 C 언어에서 문자열은 포인터pointer의 일종이기 때문에 == 연산자를 사용할 경우 두 포인터 간 주소 비교만이 수행되지, 각 주소에 보관된 문자까지는 비교하지 않는다. 포인터가 가리키는 주소를 참조하여 각 문자를 비교함으로써 문자열의 일치 여부를 확인하기 위해서는 strcmp 함수를 사용한다.
1. strcmp
strcmp 함수의 원형은 다음과 같다.
int strncmp(const char * str1, const char * str2);
str1
비교를 수행할 첫 번째 문자열이다.
str2
비교를 수행할 두 번째 문자열이다.
strcmp는 두 문자열을 서로 비교한 결과를 반환한다.
일치는 0, 사전 순서대로 볼 때 str1이 더 앞쪽에 있다면 음수, str2가 더 앞쪽에 있다면 양수를 반환한다.
/* strcmp.c */
#include <stdio.h>
#include <string.h>
int main(int argc, char * argv[])
{
char str1[64] = "codingCat"; // the 1st string
char str2[64] = "codingTiger"; // the 2nd string
char str3[64] = "codingCat"; // the 3rd string
int result = 0;
result = strcmp(str1, str3); // "codingCat" = "codingCat"
printf("compare: \"%s\" vs \"%s\" >> %d\n", str1, str3, result);
result = strcmp(str1, str2); // "codingCat" > "codingTiger"
printf("compare: \"%s\" vs \"%s\" >> %d\n", str1, str2, result);
result = strcmp(str2, str3); // "codingTiger" < "codingCat"
printf("compare: \"%s\" vs \"%s\" >> %d\n", str2, str3, result);
return 0;
}
[그림 1] strcmp.c 예제 소스 코드[그림 2] strcmp.c 예제 소스 코드의 실행 결과
주목할 사항은 strcmp의 반환 값이다. 앞서 설명한 바와 같이 두 문자열이 같다면 0을 반환하므로 0인지 아닌지만 확인할 수도 있겠지만, 두 문자열이 서로 다를 경우에 그 우선순위와 두 문자열간 거리 정보를 얻을 수 있다. 예를 들어, 위 코드를 참고하여 strcmp(str1, str2);를 실행할 경우 str1과 str2는 "coding"까지만 동일하고 그 다음 문자는 각각 'C'와 'T'로서 일치하지 않는다. 이 때,
'C'는 'T'보다 앞서므로 str1는 str2보다 앞선다. 즉, strcmp는 음수를 반환한다.
strcmp가 반환할 음수는 구체적으로 두 문자열 사이의 거리이다. 'C'는 'T'보다 17번째 앞선 문자이므로(C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T) -17을 반환한다.
strcmp의 매개변수를 바꾸었을 경우 또한 원리는 같다. 위 코드를 참고하여 strcmp(str2, str1);를 실행할 경우 str2와 str1는 "coding"까지만 동일하고 그 다음 문자는 각각 'T'와 'C'로서 일치하지 않는다. 이 때,
'T'는 'C'보다 앞서므로 str2는 str1보다 처진다. 즉, strcmp는 양수를 반환한다.
strcmp가 반환할 양수는 구체적으로 두 문자열 사이의 거리이다. 'T'는 'C'보다 17번째 뒤에 나오는 문자이므로(C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T) +17을 반환한다.
요약하면,
strcmp = 0이면 두 문자열은 일치한다.
strcmp ≠ 0이면 두 문자열은 다르다.
strcmp > 0이면 첫 번째 문자열이 두 번째 문자열보다 늦다. 절댓값을 취함으로써 서로 일치하지 않는 최초의 문자 사이의 거리를 알 수 있다.
strcmp < 0이면 첫 번째 문자열이 두 번째 문자열보다 앞선다. 절댓값을 취함으로써 서로 일치하지 않는 최초의 문자 사이의 거리를 알 수 있다.
1-1. Wide Character 확장 함수 - wcscmp
상기 strcmp는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 비교는 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.
int wcscmp (const wchar_t* wcs1, const wchar_t* wcs2);
2. strncmp
strncmp은 문자열의 일부에 대해서만 비교 연산을 수행하고 나머지 원리는 위에서 정리한 바와 같다.
[그림 3] strncmp.c 예제 소스 코드[그림 4] strcmp.c 예제 소스 코드의 실행 결과
2-1. Wide Character 확장 함수 - wcsncmp
상기 strncmp는 ASCII 문자열 또는 UTF-8 인코딩의 Unicode 문자열에 대해 사용 가능하다. UTF-16/UTF-32와 같은 Wide Character 문자열의 비교는 아래의 함수를 사용 가능하며, wchar.h, C++에서는 cwchar 헤더를 include한다.